Epidemiologic data obtained by clinical studies allow researchers to determine the likelihood of developing a certain outcome of interest within a studied population. This likelihood, or risk, can be quantified through what are known as measures of risk, which are mathematical formulas derived from contingency tables. These measures of risk include absolute risk (ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation), relative risk (RR), attributable risk, and odds ratios (OR), each of which offers different kinds of information according to the needs of the researchers.
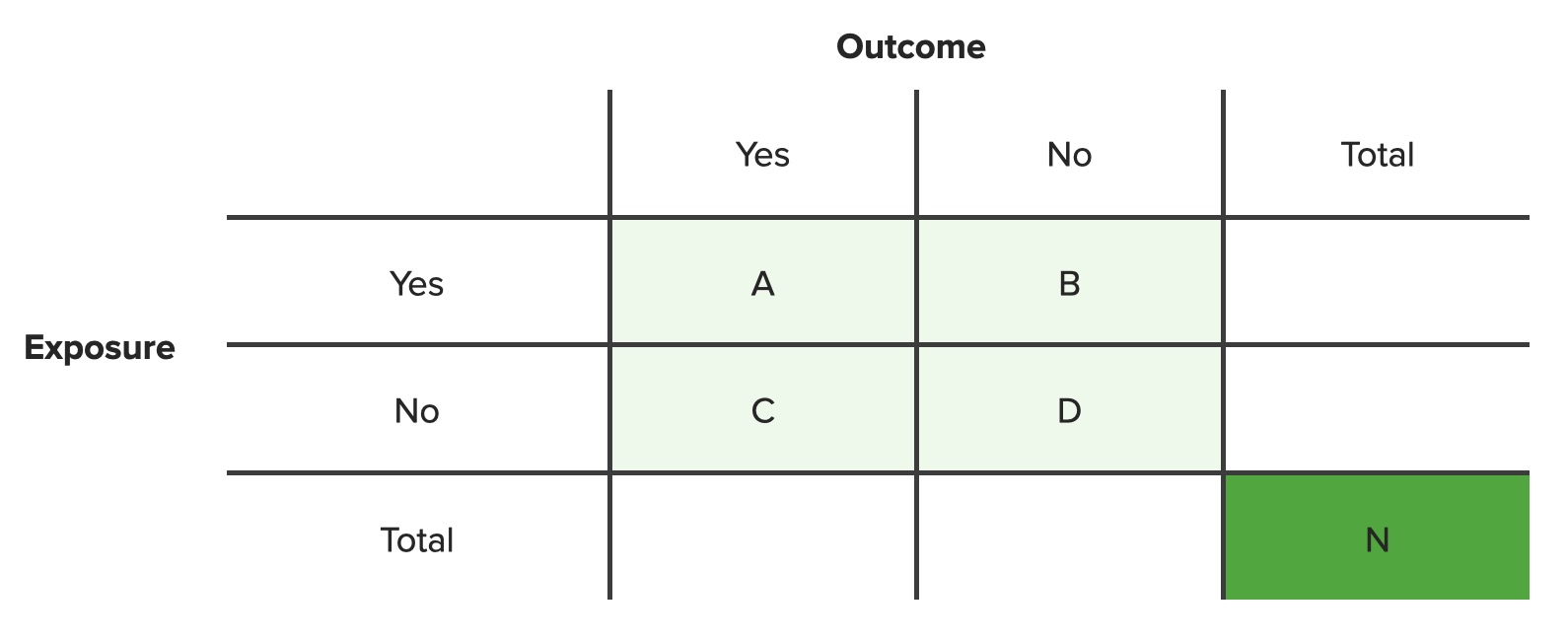
A contingency table lists the frequency distributions of variables from a study and is a convenient way to look at any relationships between variables.
Table structure
A 2×2 grid comparing whether 2 different variables are associated with each other
Each box in the table indicates the number of people in the study who have that specific combination of variables and is labeled with a letter A–D.
Formulas to calculate different measures of risk use these letters.
In order for the formulas to work, the tables need to be set up the same way each time; for clinical trials:
The rows refer to whether or not a patient was exposed to the risk factor being tested (e.g., smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases)
The columns refer to whether or not a patient developed the outcome being studied (e.g., lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer)
The “Yes” answer comes 1st, the “No” answer comes 2nd.
Letter labelsLabelsAnalogs of those substrates or compounds which bind naturally at the active sites of proteins, enzymes, antibodies, steroids, or physiological receptors. These analogs form a stable covalent bond at the binding site, thereby acting as inhibitors of the proteins or steroids.Immunoassays:
A = A patient was exposed to the risk factor and developed the outcome (e.g., a smoker develops lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer).
B = A patient was exposed to the risk factor but did not develop the outcome (e.g., a smoker does not develop lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer).
C = A patient was not exposed to the risk factor but developed the outcome anyway (e.g., nonsmoker develops lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer).
D = A patient was not exposed to the risk factor and did not develop the outcome (e.g., nonsmoker does not develop lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer).
Totals:
Each row and column has subtotals called marginal totals in the far right column and bottom row.
N is the total number of people in the population set; this grand total is reported in the bottom right box
Allows for the rapid calculation of several measures of association and risk
Example
Below is an example of a 2×2 contingency table. The cells show the frequencies of distribution (A, B, C, D) for different combinations of the two variables (outcome, exposure), for a population of size N.
Contingency table N = total number of people in set population
The ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation is the risk of developing a disease or condition after an exposure.
The ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation is also the cumulative incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency (incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency proportion, I) of exposed (or unexposed) patientsPatientsIndividuals participating in the health care system for the purpose of receiving therapeutic, diagnostic, or preventive procedures.Clinician–Patient Relationship. Cumulative incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency is a proportion, not a true rate.
Note: Both absolute risk and attributable risk (discussed below) are frequently abbreviated as ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation, which is why absolute risk is often written as incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency (I) instead.
Calculations of Absolute Risk
The ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitationis calculated as the number of people who have a particular outcome divided by the total number of people with the same exposure (or the same nonexposure). This risk can be calculated for both exposed and unexposed populations.
Steps:
Start by setting up a contingency table:
Contingency table N = total number of people in set population
Using the contingency table, the ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation in the exposed group is calculated as:
ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitationexposed = A / A + B
where A = a patient was exposed to the risk factor and developed the outcome and B = a patient was exposed to the risk factor but did not develop the outcome.
Using the contingency table, the ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation in the unexposed group is calculated as:
ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitationunexposed = C / C + D
where C = a patient who was not exposed to the risk factor but developed the outcome anyway and D = a patient who was not exposed to the risk factor and did not develop the outcome.
Example of calculating ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation
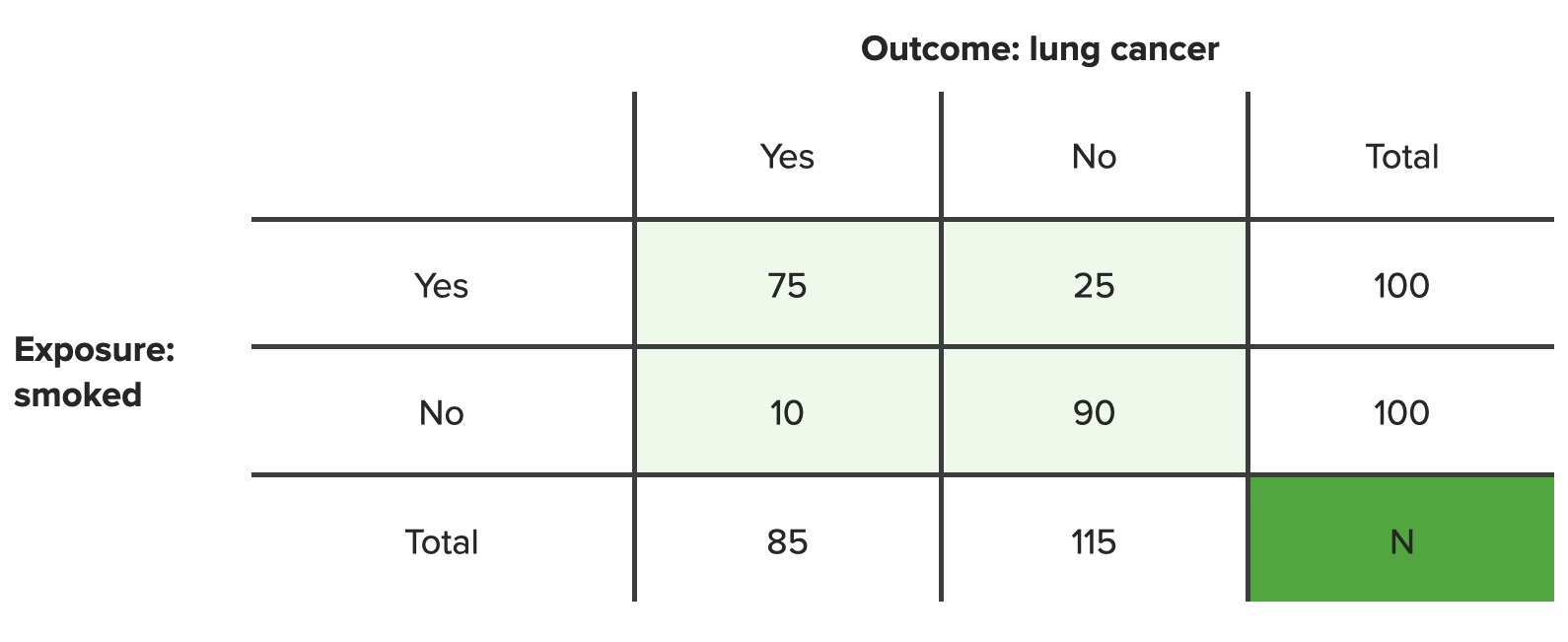
Example 1: In a population of 100 smokers, 75 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 25 did not. What is the ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation of developing lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer if you are a smoker?
This question is asking about the ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation in the exposed group
Set up a contingency table with the exposure (smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases) on the vertical axis and the outcome (lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer) on the horizontal axis (see below)
Answer: ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation = A / (A + B) = 75 / (75 + 25) = 75 / 100 = 0.75
Example 2: In a population of 100 nonsmokers, 10 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 90 did not. What is the ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation of developing lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer if you are not a smoker?
This question is asking about the ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation in the unexposed group
Set up a contingency table with the exposure (smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases) on the vertical axis and the outcome (lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer) on the horizontal axis (see below)
Answer: ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation = C / (C + D) = 10 / (10 + 90) = 10 / 100 = 0.1
Contingency table N = total number of people in set population
ARR or ARI is a measure of the reduction or increase in risk of developing a disease or condition as the result of an exposure.
Other ways to conceptualize ARR:
The difference in ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation between exposed and unexposed groups
The difference in cumulative incidences.
The differencebetween the percentage of subjects who have a condition in both exposed and unexposed groups.
ARR can be interpreted as the health “gained” or ”lost” as a result of the exposure. For example, if you don’t smoke, by what percent can you reduce your risk of lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer?
The ARR between the exposed and unexposed groups can be calculated as:
ARR = Iexposed – Iunexposed
where I = cumulative incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency. Because I is the same as ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation, this formula can be calculated from a contingency table:
ARR = [A / (A + B)] – [C / (C + D)]
Example of calculating ARR
In a population of 100 smokers, 75 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 25 did not. In a population of 100 nonsmokers, 10 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 90 did not. By how much does not smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases reduce the ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation of developing lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer?
This question is asking about the ARR achieved by avoidance of the exposure (smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases).
Set up a contingency table with the exposure (smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases) on the vertical axis and the outcome (lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer) on the horizontal axis (see below).
Answer:
ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic RegurgitationExposed = A / (A + B) = 75 / (75 + 25) = 75 / 100 = 0.75
ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic RegurgitationUnexposed = C / (C + D) = 10 / (10 + 90) = 10 / 100 = 0.1
ARR = IExposed ‒ IUnexposed = ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic RegurgitationExposed ‒ ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic RegurgitationUnexposed = 0.75 ‒ 0.1 = 0.65
Interpretation: Based on this data set, not smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases lowers a person’s absolute risk of developing lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer by 65 percentage points (from 75% to 10%). An absolute risk differenceAbsolute risk differenceNumber Needed to Treat is expressed in percentage points, not as a percent reduction.
Contingency table N = total number of people in set population
Number needed to treatNumber needed to treatThe number needed to treat (NNT) is the number of patients that are needed to treat to prevent 1 additional adverse outcome (e.g., stroke, death). For example, if a drug has an NNT of 10, it means 10 people must be treated with the drug to prevent 1 additional adverse outcome. Number Needed to Treat/harm
These are numbers typically reported when testing new therapeutic options. In these cases:
The “exposure” is the new medication/procedure.
The “outcome” is either the benefit of the procedure or a potential adverse effect.
Number needed to treatNumber needed to treatThe number needed to treat (NNT) is the number of patients that are needed to treat to prevent 1 additional adverse outcome (e.g., stroke, death). For example, if a drug has an NNT of 10, it means 10 people must be treated with the drug to prevent 1 additional adverse outcome. Number Needed to Treat (NNTNNTThe number needed to treat (NNT) is the number of patients that are needed to treat to prevent 1 additional adverse outcome (e.g., stroke, death). For example, if a drug has an nnt of 10, it means 10 people must be treated with the drug to prevent 1 additional adverse outcome.Number Needed to Treat):
Represents the number of patientsPatientsIndividuals participating in the health care system for the purpose of receiving therapeutic, diagnostic, or preventive procedures.Clinician–Patient Relationship who would need to be treated for 1 additional patient to benefit (i.e., for 1 additional adverse outcome to be prevented).
NNTNNTThe number needed to treat (NNT) is the number of patients that are needed to treat to prevent 1 additional adverse outcome (e.g., stroke, death). For example, if a drug has an nnt of 10, it means 10 people must be treated with the drug to prevent 1 additional adverse outcome.Number Needed to Treat = 1 / ARR (i.e., the inverse of the ARR)
By convention, the NNTNNTThe number needed to treat (NNT) is the number of patients that are needed to treat to prevent 1 additional adverse outcome (e.g., stroke, death). For example, if a drug has an nnt of 10, it means 10 people must be treated with the drug to prevent 1 additional adverse outcome.Number Needed to Treat is rounded up to the next whole number.
Number needed to harmNumber needed to harmThe NNH is the additional number of individuals who need to be exposed to risk (harmful exposure or treatment) to have 1 extra person develop the disease compared to that in the unexposed group.Number Needed to Treat (NNHNNHThe NNH is the additional number of individuals who need to be exposed to risk (harmful exposure or treatment) to have 1 extra person develop the disease compared to that in the unexposed group.Number Needed to Treat):
Typically used when reporting on experimental treatments with potential adverse effects
Represents the number of patientsPatientsIndividuals participating in the health care system for the purpose of receiving therapeutic, diagnostic, or preventive procedures.Clinician–Patient Relationship who would need to be treated for 1 additional patient to be harmed.
NNHNNHThe NNH is the additional number of individuals who need to be exposed to risk (harmful exposure or treatment) to have 1 extra person develop the disease compared to that in the unexposed group.Number Needed to Treat = 1 / ARI (i.e., the inverse of the ARI)
Relative Risk
Definition
Relative risk (RR)is the risk of a disease or condition occurring in a group or population with a particular exposure relative to a control (unexposed) group.
Can be equivalently stated asthe risk of developing the disease after an exposure compared to the risk of developing the disease without exposure.
RR shows how strongly exposure is associated with the risk of the disease.
Calculations of RR
RR is typically among the most important numbers calculated. Cohort studiesCohort studiesStudies in which subsets of a defined population are identified. These groups may or may not be exposed to factors hypothesized to influence the probability of the occurrence of a particular disease or other outcome. Cohorts are defined populations which, as a whole, are followed in an attempt to determine distinguishing subgroup characteristics.Epidemiological Studies are the only type of observationalstudy that can determine the RR.
The relative risk is calculated as the frequency of a disease or condition in the exposed group (IE) divided by the frequency in an unexposed control group (IO), which is represented by the formula:
RR = IE / IO
Again, since the cumulative incidences are the same as the ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation, the RR can be calculated from a contingency table by using the following expanded formula:
RR = [A / (A + B)] / [C / (C + D)]
Interpretation of RR
RR = 1: The risk of the outcome for the exposed group and the unexposed group is the same.
RR > 1: The risk of the exposed group is greater than the risk of the unexposed group; evidence of positive association/possible causal factor.
RR < 1: The risk of the exposed group is lower than the risk of the unexposed group; evidence of negative association/possible protective factor.
Example of calculating RR
In a population of 100 smokers, 75 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 25 did not. In a population of 100 nonsmokers, 10 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 90 did not. What is the risk of getting lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer if you smoke compared to the risk of getting lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer if you do not smoke?
This question is asking about the RR of getting lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer
Set up a contingency table (see below)
Answer:
RR = IE ÷ IO = ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic RegurgitationExposed ÷ ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic RegurgitationUnexposed = [ A / (A + B) ] ÷ [ C / (C + D) ]
RR = 0.75 ÷ 0.1 = 7.5
Interpretation: Based on this data sample, smokers are 7.5 times as likely to develop lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer as nonsmokers (equivalent to a 650% relative increase in risk).
Contingency table N = total number of people in set population
The RRR is defined as the reduction (or increase) in risk of a particular outcome, in a group with a known exposure, relative to the unexposed control group.
Put another way: RRR is the proportion of baseline risk that is reduced through nonexposure.
Example: If people don’t smoke, how much less lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer can you expect?
Calculation:
The RRR is calculated as the difference between the incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency of a disease in an exposed (IE) and an unexposed (IO ) group divided by the incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency in the unexposed group, which is calculated with the following formula:
In a population of 100 smokers, 75 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 25 did not after 10 years in a cohort study. In a population of 100 nonsmokers, 10 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 90 did not. If people didn’t smoke, how much less lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer can be expected in the population?
This question is asking about the RRR achieved by not smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases.
Set up a contingency table (see below).
Answer: RRR = ARR ÷ IE = 0.65 ÷ 0.75 = 0.867
Interpretation: Based on this data set, avoiding smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases reduces the relative risk of lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer by 86.7%. (Dividing the ARR by IO instead yields 6.5, or 650%; that value is the relative risk increase [RRI] associated with smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases, not a risk reduction.)
Contingency table N = total number of people in set population
The attributable risk is a measure of the risk of developing an outcome associated with a particular exposure.
That is, how much of the outcome can we attribute to the behavior?
Attributable risk is sometimes called the excess risk because it represents how much increase in risk a particular behavior will add to the baseline risk of developing a particular outcome.
The formula for attributable risk is similar to that for ARR, but attributable risk is used in epidemiologic studies.
2 kinds of attributable risk:
Attributable risk in the exposed group
Population attributable risk (PAR)
Note: Both absolute risk and attributable risk are frequently abbreviated as ARARAortic regurgitation (AR) is a cardiac condition characterized by the backflow of blood from the aorta to the left ventricle during diastole. Aortic regurgitation is associated with an abnormal aortic valve and/or aortic root stemming from multiple causes, commonly rheumatic heart disease as well as congenital and degenerative valvular disorders. Aortic Regurgitation, which is why absolute risk is often described as incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency (I) instead.
Attributable risk in the exposed group
The attributable risk in the exposed group is the difference in the rate of a disease between the exposed and the unexposed groups. For example, what percentage of lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer cases are likely due to smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases? The attributable risk is calculated by subtracting the incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency in the unexposed group (IO) from the incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency of the exposed group (IE) and dividing by the incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency in the exposed group, which is expressed as:
Example: In a population of 100 smokers, 75 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 25 did not after 10 years in a cohort study. In a population of 100 nonsmokers, 10 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 90 did not. What percentage of lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer cases among smokers are likely due to smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases?
This question is asking about the attributable risk in the exposed group.
Interpretation: Among smokers, 86.7% of lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer cases are attributable to smokingSmokingWillful or deliberate act of inhaling and exhaling smoke from burning substances or agents held by hand.Interstitial Lung Diseases.
Contingency table N = total number of people in set population
The PAR is the attributable risk for an entire population. It is the excess incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency in the total population that is attributable to the exposure. When it is expressed as a proportion of the total incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency, it is called the population attributable fraction (PAR%), which represents the fraction of cases that would not occur in the population if the exposure were eliminated.
For example, what percentage of lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer cases could be prevented if nobody smoked?
The PAR is calculated by subtracting the incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency rate in the unexposed population from the incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency rate in the entire population:
PAR = (IT – IO) / IT = {[(A + C) / N] – [C / (C + D)]} / [(A + C) / N]
Example: In a population of 100 smokers, 75 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 25 did not after 10 years in a cohort study. In a population of 100 nonsmokers, 10 developed lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer and 90 did not. What percentage of lung cancerLung cancerLung cancer is the malignant transformation of lung tissue and the leading cause of cancer-related deaths. The majority of cases are associated with long-term smoking. The disease is generally classified histologically as either small cell lung cancer or non-small cell lung cancer. Symptoms include cough, dyspnea, weight loss, and chest discomfort. Lung Cancer cases could be prevented if nobody smoked?
This question is asking about the population attributable risk.
Answer: 76.5% of lung cancers could be prevented if no one smoked
An odds ratio (OR) is a statistic that quantifies the strength of association between 2 variables or events.
OR calculates the odds of one variableVariableVariables represent information about something that can change. The design of the measurement scales, or of the methods for obtaining information, will determine the data gathered and the characteristics of that data. As a result, a variable can be qualitative or quantitative, and may be further classified into subgroups.Types of Variables (A) in the presence or absence of another variableVariableVariables represent information about something that can change. The design of the measurement scales, or of the methods for obtaining information, will determine the data gathered and the characteristics of that data. As a result, a variable can be qualitative or quantitative, and may be further classified into subgroups.Types of Variables (B).
Odds are the probabilityProbabilityProbability is a mathematical tool used to study randomness and provide predictions about the likelihood of something happening. There are several basic rules of probability that can be used to help determine the probability of multiple events happening together, separately, or sequentially.Basics of Probability of a thing happening divided by the probabilityProbabilityProbability is a mathematical tool used to study randomness and provide predictions about the likelihood of something happening. There are several basic rules of probability that can be used to help determine the probability of multiple events happening together, separately, or sequentially.Basics of Probability of that thing not happening.
For example, the probabilityProbabilityProbability is a mathematical tool used to study randomness and provide predictions about the likelihood of something happening. There are several basic rules of probability that can be used to help determine the probability of multiple events happening together, separately, or sequentially.Basics of Probability of “heads” on a coin toss is 50%; the odds are 1 (50% ÷ 50%).
In clinical studies, OR measures the association between an exposure and an outcome.
Does not imply causation
OR can be used to estimate the RR when incidenceIncidenceThe number of new cases of a given disease during a given period in a specified population. It also is used for the rate at which new events occur in a defined population. It is differentiated from prevalence, which refers to all cases in the population at a given time.Measures of Disease Frequency rates cannot be calculated, such as in case–control studies.
Used when diseases are rare (typically when the prevalencePrevalenceThe total number of cases of a given disease in a specified population at a designated time. It is differentiated from incidence, which refers to the number of new cases in the population at a given time.Measures of Disease Frequency is ≤ about 10%)
Also used in more complicated statistical analyses:
Can be thought of as a type of RR
Used to determine risk factors in studies
Calculations of the OR
An OR is used as an estimation of RR in case–control studies. OR is calculated by determining the odds of exposure among the diseased divided by the odds of exposure among the undiseased. This is represented as:
OR = Odds of exposure among disease / Odds of exposure among undiseased = (A / C) / (B / D)
where (A ÷ C) represents the number of exposed cases divided by the number of unexposed cases among those with the disease and (B ÷ D) is the number of exposed undiseased divided by the number of unexposed undiseased.
Rearranging the formula gives the simplified equation:
OR = ADADThe term advance directive (AD) refers to treatment preferences and/or the designation of a surrogate decision-maker in the event that a person becomes unable to make medical decisions on their own behalf. Advance directives represent the ethical principle of autonomy and may take the form of a living will, health care proxy, durable power of attorney for health care, and/or a physician’s order for life-sustaining treatment.Advance Directives / BC
Interpreting the OR
OR is interpreted in the same way as RR:
OR = 1:
The risk of the outcome for the exposed group and the unexposed group is the same.
No association between the exposure and outcome
OR > 1:
The risk in the exposed group is greaterthan the risk of the unexposed group.
Evidence of a positive association/possible causal factor
OR < 1:
The risk in the exposed group is lowerthan the risk in the unexposed group.
Evidence of a negative association/possible protective factor
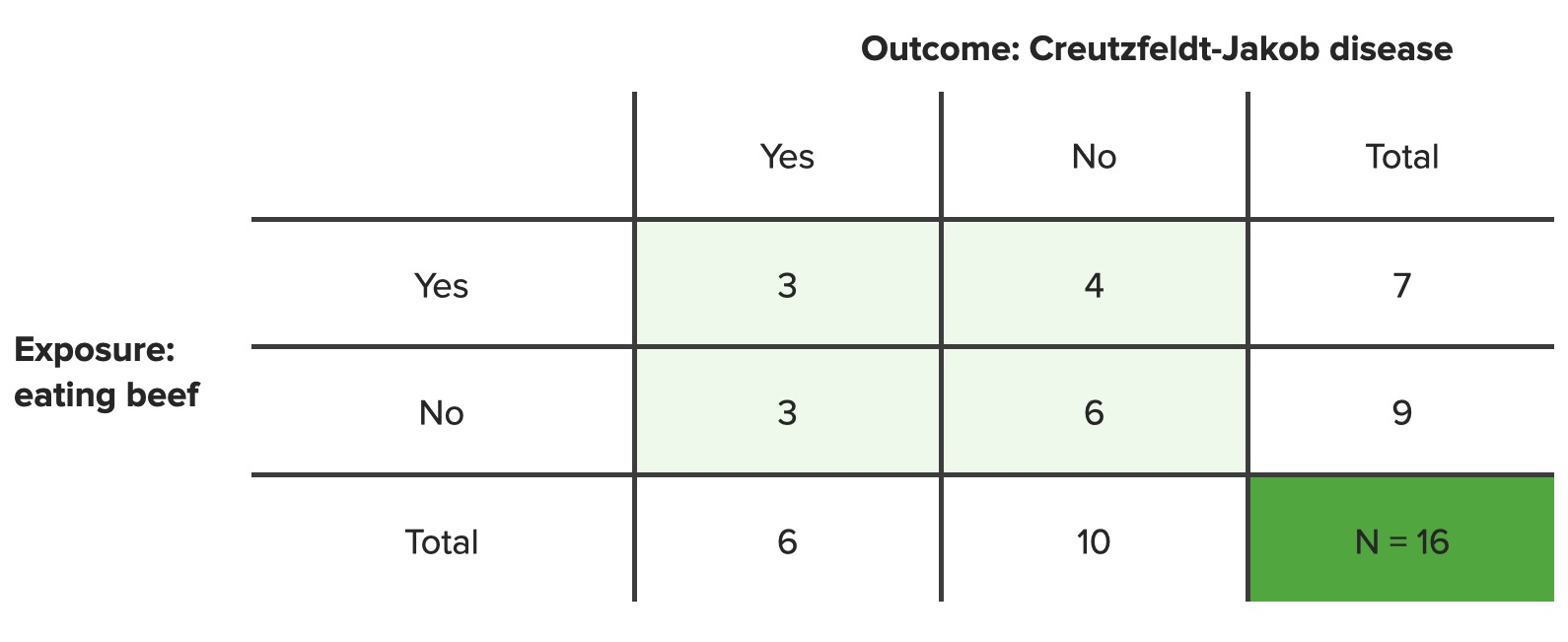
Answer: OR = (ADADThe term advance directive (AD) refers to treatment preferences and/or the designation of a surrogate decision-maker in the event that a person becomes unable to make medical decisions on their own behalf. Advance directives represent the ethical principle of autonomy and may take the form of a living will, health care proxy, durable power of attorney for health care, and/or a physician’s order for life-sustaining treatment.Advance Directives) ÷ (BC) = (3 x 6) ÷ (3 x 4) = 18 ÷ 12 = 1.5
Interpretation: The odds of developing vCJDvCJDTransmissible Spongiform Encephalopathies are 50% higher in the group that ate beef, supporting the idea that eating beef is a risk factor for the development of CJD.
Contingency table N = total number of people in set population Note: These are hypothetical data; the true incidence rates of Creutzfeldt-Jakob disease are much lower than these data suggest.