A potência estatística é a probabilidade de detetar um efeito quando esse efeito existe genuinamente na população. Com o resto mantendo-se igual, um teste baseado numa amostra grande tem maisMAISAndrogen Insensitivity Syndrome poder estatístico do que um teste que envolve uma amostra pequena. Há também formas de aumentar a potência sem aumentar o tamanho da amostra. A maioria dos estudos publicados tem baixa potência estatística, o que pode levar a erros sérios na interpretação dos resultados.
A potência estatística (PE) é expressa de 3 formas diferentes:
PE é a probabilidade de encontrar significância se a hipótese alternativa for verdadeira.
PE é a probabilidade de rejeitar corretamente uma hipótese nula falsa, onde a hipótese nula é a hipótese de que não há diferenças significativas entre populações especificadas (por exemplo, grupos de controlo versus experimental).
PE = 1 – beta (β), onde β = erro tipo II (falso negativo), equivalente a 1 – sensibilidade. Quanto maior a potência de um estudo clínico experimental, maisMAISAndrogen Insensitivity Syndrome prontamente detetará um efeito do tratamento quando este realmente existir.
Baixa potência estatística
Menos de 13% dos 31.873 ensaios clínicos publicados entre 1974 e 2017 tinham uma PE adequada. Um estudo com PE baixa significa que os resultados do teste são questionáveis e apresentam problemas potencialmente graves, incluindo:
Uma chance reduzida de detetar um efeito verdadeiro, genuíno e significativo na população da amostra, o que pode bloquear a busca de maisMAISAndrogen Insensitivity Syndrome estudos
Menor probabilidade de que um resultado estatisticamente significativo reflita um efeito verdadeiro (por exemplo, maisMAISAndrogen Insensitivity Syndrome falsos positivos)
Sobreestimação do verdadeiro tamanho do efeito (ES, pela sigla em inglês) do tratamento
Baixa reprodutibilidade
Possível violação de princípios éticos:
Pacientes e voluntários saudáveis continuam a participar em estudos que podem ter valor clínico limitado.
Sacrifício desnecessário de animais na investigação
Caos na interpretação de estudos com amostras pequenas usando a mesma metodologia, mas que produzem resultados conflituosos
Estudos com muita PE, também chamados de “estudos sobrecarregados”, também podem ser problemáticos pelos seguintes motivos:
Podem ser enganadores, pois têm o potencial de mostrar significância estatística e também diferenças clínicas sem importância/irrelevantes
Resulta em desperdício de recursos
Pode ser antiético devido ao envolvimento de seres humanos e/ou animais de laboratório para experiências desnecessárias
Características
A potência estatística tem relevância apenas quando a hipótese nula pode ser rejeitada e é determinada pelas seguintes variáveis:
Alfa (α)
Beta (β)
Desvio padrão (DP) da população
Tamanho da amostra
ES do tratamento
Alfa
Alfa é a chance de testar positivo num teste de diagnóstico entre aqueles sem a doença/resultado, causando um erro tipo I ou um “falso positivo”.
Alfa = chance de rejeitar a hipótese nula entre aqueles que satisfazem a hipótese nula
Alfa = 1 – especificidade = “p-valueP-valueThe p-value is the probability of obtaining a given result, assuming the null hypothesis is true.Statistical Tests and Data Representation” = “o nível de significância”
Beta está diretamente relacionado com a PE do estudo (PE = 1 – β).
Num nível beta de 0,2, 20% das amostras podem perder uma diferença realmente significativa.
A maioria dos estudos usa um ponto de corte beta de 20% (0,2).
Ao contrário de alfa, há um valor diferente de beta para cada valor médio diferente da hipótese alternativa; assim, beta depende tanto do valor de corte estabelecido pelo alfa quanto da média da hipótese alternativa.
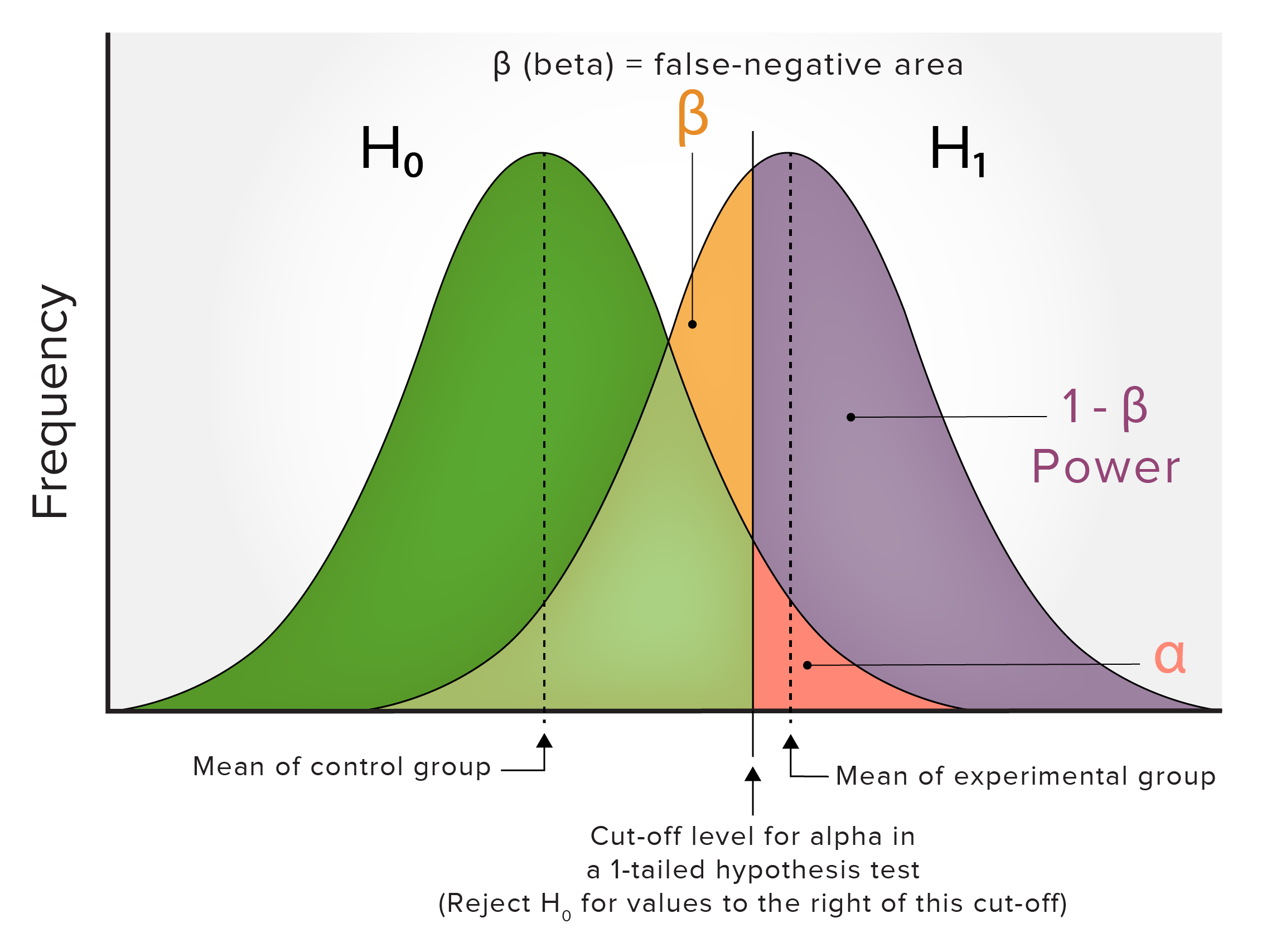
Relação entre alfa e beta
A relação entre alfa e beta é frequentemente representada em gráficos que mostram:
2 populações ou distribuições normalizadas:
Um grupo de controlo
Um grupo experimental (que pode ter uma média estatisticamente significativa e diferente)
H0: a hipótese nula, que afirma que existe apenas 1 média verdadeira (do grupo de controlo) e que qualquer variação encontrada na amostra/grupo experimental se deve apenas à variação aleatória normal na distribuição
H1: a hipótese alternativa, que é uma afirmação que contradiz diretamente a hipótese nula afirmando que o valor real de um parâmetro populacional é menor ou maior que o valor declarado na hipótese nula
Alfa (α): a área falso-positiva (geralmente mostrada como um teste de hipótese de 2 caudas)
Este é um gráfico de 2 populações ou distribuições normalizadas de um grupo de controlo (verde) e um grupo experimental (roxo) com uma diferença média estatisticamente significativa. Veja o texto para explicação acerca da simbologia utilizada.
Existe uma relação inversa entre alfa e beta. Se o beta for diminuído:
A área de alfa aumenta.
O número de falsos negativos ou erros do tipo II diminui.
O número de falsos positivos ou erros do tipo I aumenta.
A relação inversa de alfa e beta também pode ser apreciada numa tabela de contingência 2 x 2 que compara os achados positivos e negativos da realidade versus um estudo.
Achados realmente positivos
Achados realmente negativos
Resultados positivos no estudo
Verdadeiros positivos (potência, 1 – β)
Falsos positivos (erro tipo I, α)
Achados negativos no estudo
Falsos negativos (erro tipo II, β)
Verdadeiros negativos
Desvio padrão da população
O desvio padrão é uma medida da quantidade da variação ou da dispersão de um conjunto de valores em relação à média.
Calculado como a raiz quadrada da variância, que é a média das diferenças quadradas da média.
Quanto maior o DP, maisMAISAndrogen Insensitivity Syndrome pacientes são necessários numa amostra para demonstrar uma diferença estatisticamente significativa.
Tamanho da amostra
O tamanho da amostra é o número de observações numa amostra.
Uma amostra maior representará melhor a população; assim, a potência do teste aumentará naturalmente.
Para um teste t bicaudal de 2 amostras com um nível alfa de 0,05, a fórmula simples abaixo fornecerá um tamanho aproximado de amostra necessário para ter uma potência estatística de 80% (beta = 0,2):
$$ n = \frac{16s^{2}}{d^{2}} $$
onde n = tamanho de cada amostra, s = desvio padrão (assume-se que é o mesmo em cada grupo) e d = diferença a ser detetada. A mnemónica, como sugerida pelo criador da fórmula, Robert Lehr, é “ 16 s-quadrado sobre d-quadrado. ” (Nota: “s-quadrado” também é conhecido como variância).
Exemplos:
Encontre o número aproximado de pacientes com hipertensão estádio I (sistólica 130–139 mm Hg ou diastólica 80–89 mm Hg) necessários para fornecer uma potência de 80% para detetar uma diferença de 15 mm Hg de PA diastólica nos tratamentos A e B usando uma amostra dupla, bicaudal, teste alfa = 0,05 t, dado que o desvio padrão esperado para cada grupo é de 15 mm Hg. Resposta: O tamanho aproximado da amostra n = “16 s-quadrado sobre d-quadrado” = 16 x 152/152 = 16 x 225/225 = 16 pessoas em cada grupo. Observe que um dos “tratamentos” geralmente é definido como o grupo de controlo (não tratado).
Para reverter a situação: em 2 grupos com 16 pacientes cada com hipertensão estádio I, foi encontrada uma diferença de 15 mm Hg após tratamento depois de os pacientes de cada grupo terem sido tratados com 2 tratamentos diferentes. Se alfa = 0,05 e beta = 0,2, o tamanho da amostra foi suficiente para detetar uma diferença significativa? Resposta: n = 16 x 152/152 = 16 pessoas em cada grupo. Então, sim, o tamanho da amostra foi suficiente.
Na questão 1, qual seria o número aproximado de pacientes necessários, se o investigador quisesse detetar uma diferença de 7,5 mm Hg em vez de uma diferença de 15 mm Hg, com todos os outros parâmetros permanecendo os mesmos? Resposta: n = 16 x 152/7,52 = 16 x 225/56,25 = 64 pessoas em cada grupo Neste último exemplo, observe que, para detetar metade da diferença, você precisa de 4 vezes o tamanho da amostra, o que fica evidente pela fórmula simples.
Tamanho do efeito do tratamento
O tamanho do efeito é a diferença da média padronizada entre 2 grupos, que é exatamente equivalente ao “Z-scoreZ-scoreStandard deviation difference between patient’s bone mass density and that of age-matched population.Osteoporosis” de uma distribuição normal padrão.
Se a diferença entre os 2 tratamentos for pequena, serão necessários maisMAISAndrogen Insensitivity Syndrome pacientes para detetar uma diferença.
Outras situações que possuem ESs:
A correlação entre 2 variáveis
O coeficiente de regressão num cálculo de regressão
O risco de um evento específico (por exemplo, acidente vascular cerebral)
Cálculo do ES com d de Cohen:
O d de Cohen é o método maisMAISAndrogen Insensitivity Syndrome comum (mas imperfeito) para calcular o ES. d de Cohen = diferença estimada nas médias/(desvios padrão estimados agrupados), onde:
$$ {DP = \sqrt{\frac{(DP1^{2} + DP2^{2})}{2}}} $$
Se os DPs forem iguais em cada grupo, então d = diferenças médias/DP. Por exemplo, se a diferença for 150 e o DP for 50, então d = 150/50 = 3, que é um ES grande.
Interpretação do d de Cohen:
ES pequeno: Se d = 0,2, o score ou valor do sujeito médio do grupo experimental é 0,2 DP acima do valor do sujeito médio do grupo de controlo, superando os valores de 58% do grupo de controlo.
ES médio: Se d = 0,5, o valor do sujeito médio no grupo experimental é 0,5 DPs acima do valor do sujeito médio no grupo de controlo, superando os valores de 69% do grupo de controlo.
ES grande: Se d = 0,8, o valor do sujeito médio é 0,8 DPs acima do valor do sujeito médio do grupo de controlo, superando os valores de 79% do grupo de controlo.
Resumo das características
Em resumo, a PE tenderá a ser maior quando:
O ES (diferença entre grupos) é grande.
O tamanho da amostra é grande.
Os DPs das populações são pequenos.
O nível de significância alfa é maior (por exemplo, 0,05 em vez de 0,01).
O ponto de corte beta é baixo (por exemplo, 0,1 versus 0,2).
Usa-se o teste de 1 cauda em vez de um teste de 2 caudas.
No entanto, a hipótese direcional não consegue detetar uma diferença que esteja na direção oposta.
Este teste raramente é usado.
Erros Comuns
Rejeitar uma hipótese nula (por exemplo, há uma diferença significativa) sem considerar a significância prática/clínica do achado do estudo
Aceitar uma hipótese nula (por exemplo, não rejeitar uma hipótese nula) quando um resultado NÃO é estatisticamente significativo, sem ter em consideração a potência
Ser convencido por um estudo de investigação com baixa potência
Negligenciar a realização de uma análise de potência/cálculo do tamanho da amostra
Não corrigir para inferência múltipla ao calcular a potência:
Inferência múltipla é o processo de realizar maisMAISAndrogen Insensitivity Syndrome de 1 teste de inferência estatística no mesmo conjunto de dados.
A execução de vários testesTestesGonadal Hormones no mesmo conjunto de dados no mesmo estádio de análise aumenta a chance de obter pelo menos 1 resultado inválido.
Usando ESs padronizados (por exemplo, os ESs pequenos, médios e grandes do d de Cohen) em vez de considerar os detalhes do projeto experimental em si. Às vezes, uma experiência pode ter uma pequena classificação de Cohen, mas ser uma experiência melhor.
Potência retrospetiva confusa (calculado após a colheita de dados) e potência prospectiva
Análise
Uma análise da potência responde a 2 grandes questões:
Quanto DP é considerado adequado?
Qual é o tamanho da amostra que será necessário?
Quanta potência estatística é considerada adequada?
Tradicionalmente, o nível mínimo de potência é 80% (ou 0,80), assim como o valor arbitrário de 5% (ou 0,05) é o corte alfa mínimo tradicional para definir o p-value em 0,05.
Um nível de potência de 80% significa que há uma probabilidade de 20% de encontrar um erro tipo II (falso negativo).
Este nível aceitável de 20% de ter erros do tipo II é 4 vezes maior do que a probabilidade de 5% de encontrar um erro do tipo I (falso positivo) para o valor padrão para o nível de significância.
Os erros do tipo I são geralmente considerados piores do que os erros do tipo II.
Uma amostra grande o suficiente para detetar um efeito de importância científica prática para garantir uma probabilidade alta o suficiente para que uma hipótese nula falsa seja rejeitada
A análise de potência deve ser realizada antes do início de uma experiência.
Não se pode continuar a adicionar sujeitos a uma experiência completa que teve um p-value quase significativo.
Esta prática é desaprovada e constitui o que é chamado de “p-hacking” ou “dragagem de dados”.
Calculando o tamanho de amostra adequado para um teste t de amostras independentes:
Estime (por estudo piloto ou dados históricos) as médias populacionais dos 2 grupos ou a diferença entre as médias, que deve ser o menor ES de interesse científico.
Estime (por estudo piloto ou dados históricos) os DPs populacionais dos 2 grupos.
Decida quais os níveis de alfa (por exemplo, 0,05) e beta (por exemplo, 0,2) que são desejados.
Insira esses valores (alfa, beta, as 2 médias estimadas e o DP agrupado estimado) numa calculadora de DP online confiável para obter o tamanho da amostra.
Os cálculos são um pouco complexos e são sempre feitos usando um computador.
Pode calcular-se um tamanho aproximado da amostra usando a fórmula n = 16s2/d2, conforme discutido acima.
Exemplos de Cálculos e Análises de Poder Estatístico
Cenário 1
Um ensaio de um novo fertilizante chamado “Grow-A-Lot” foi dado a um produtor de tomate para determinar se são produzidos maisMAISAndrogen Insensitivity Syndrome tomates por planta com o novo fertilizante em comparação com plantas não fertilizadas. O agricultor pegou em 200 sementes de tomate de um balde das suas sementes habituais e dividiu-as em 2 grupos:
Um grupo de 100 sementes que não recebeu fertilizante (o grupo de controlo)
Um grupo de 100 sementes que receberam fertilizante (o grupo experimental)
A hipótese nula é que ambos os grupos de plantas produziriam o mesmo número de tomates por planta, enquanto a hipótese alternativa seria que as plantas que receberem o fertilizante produziriam um número diferente de tomates.
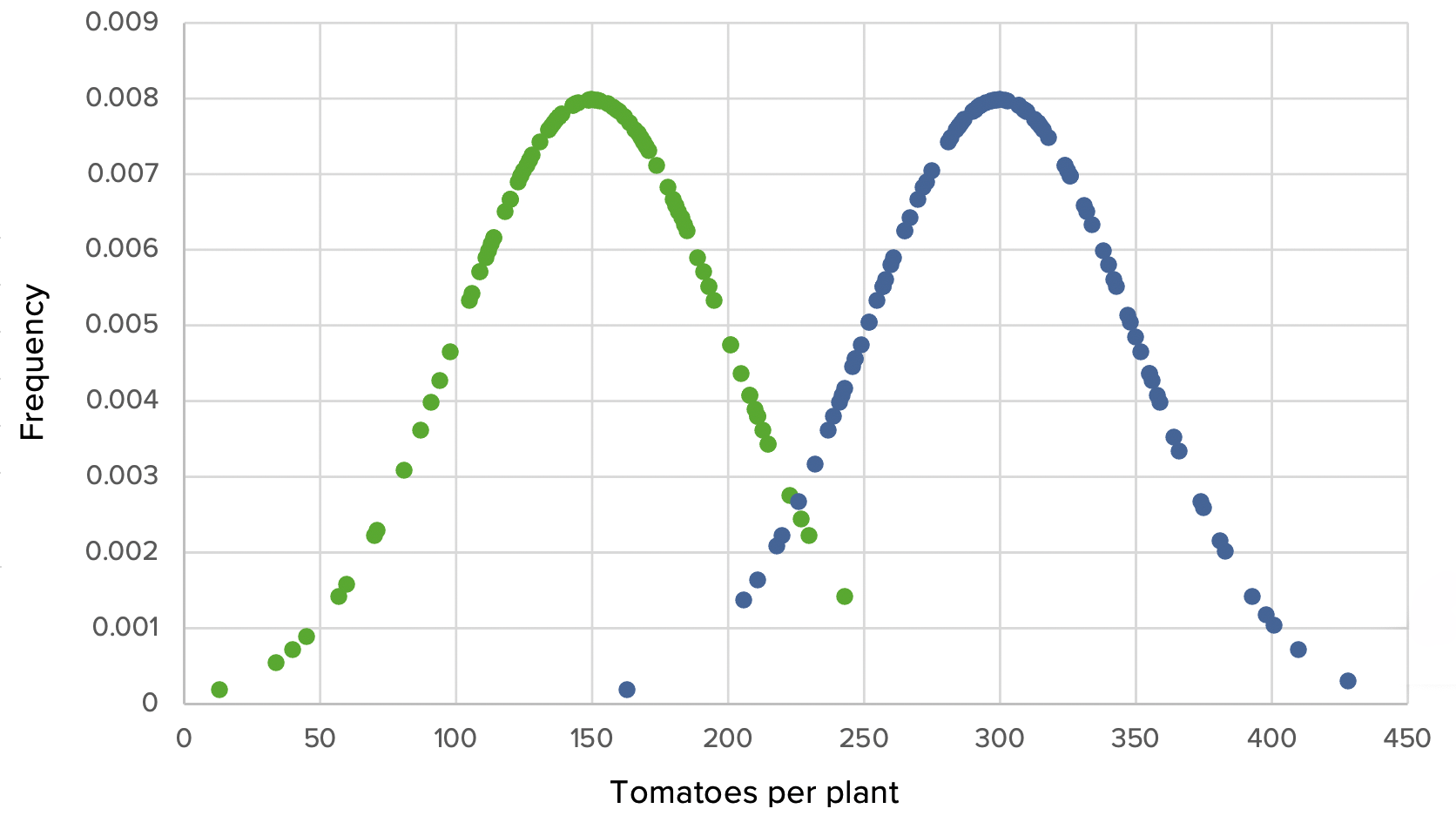
Ensaio 1 com tamanhos de amostra grandes:
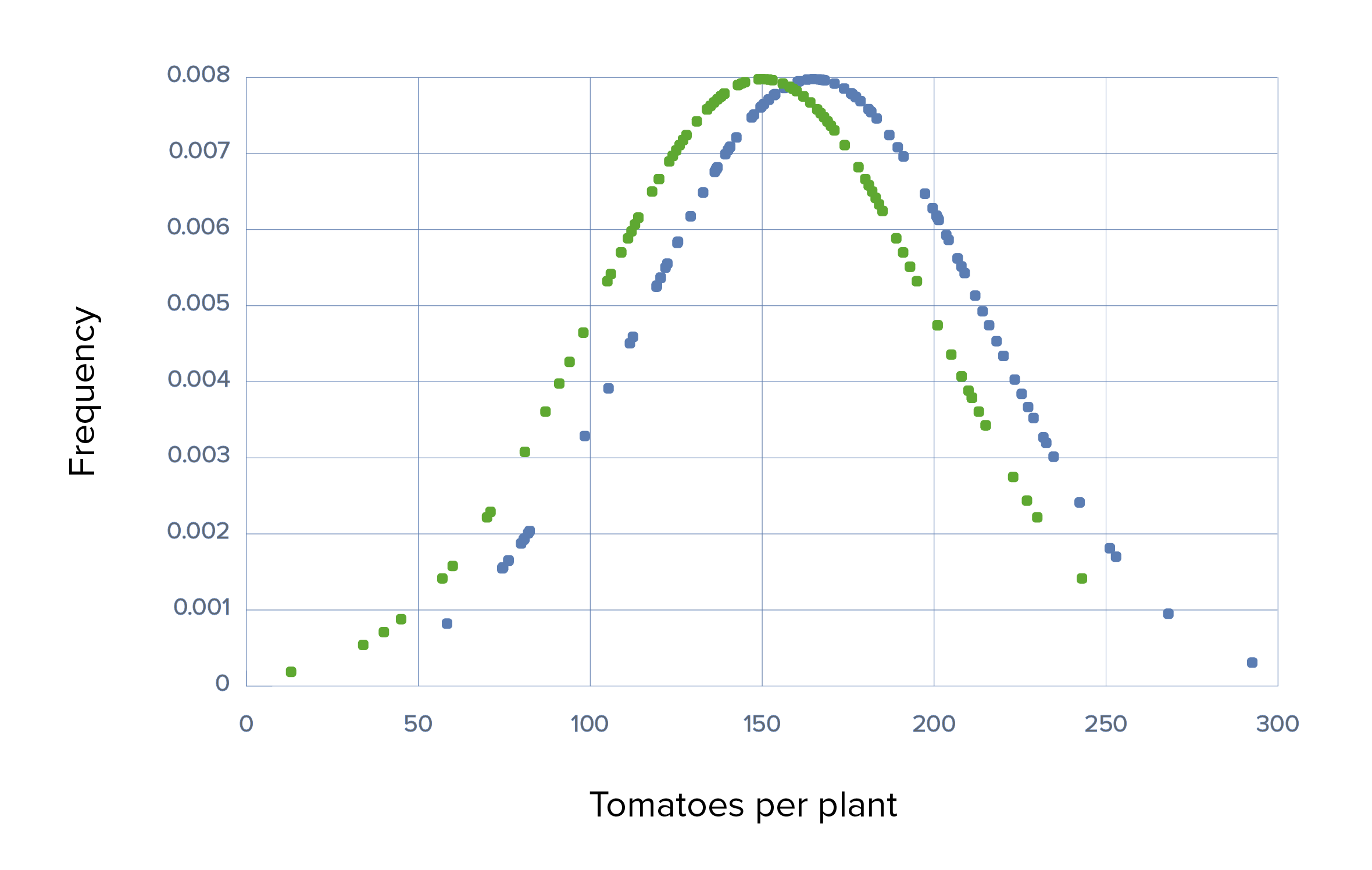
O grupo fertilizado produziu em média o dobro do número de tomates (300) que o grupo de controlo (150). Há também uma pequena sobreposição, uma vez que algumas plantas do grupo de controlo tiveram um desempenho superior às outras do grupo, enquanto algumas plantas do grupo experimental tiveram desempenho inferior. Apenas uma visão rápida sobre o gráfico é convincente o suficiente para notar que há uma diferença óbvia, mas foi realizado um teste t para confirmar que a diferença era estatisticamente significativa, com um p-value muito baixo.
Ensaio 1, cenário 1: Gráfico que demonstra que o uso de Grow-A-Lot com tamanho de efeito grande, DPs grandes, médias de 150 vs. 300, DP de 50 em cada e tamanhos de amostra grandes de 100
Verde: grupo de controlo Azul: grupo experimental
As 100 plantas do grupo de controlo resultaram numa média de 150 tomates por planta. Enquanto as 100 plantas que receberam fertilizantes produziram significativamente mais tomates com uma média de 300 tomates por planta. O resultado é significativo para um p-value de < 0,05, então a hipótese nula é rejeitada.
Mesmo que a experiência seja repetida 1000 vezes, seria extremamente improvável que o agricultor escolhesse aleatoriamente um conjunto diferente de sementes da região de sobreposição para obter um resultado diferente. O efeito de grandes tamanhos por si só dá a este ensaio uma grande quantidade de DP porque seria extremamente improvável que a repetição da amostragem produzisse um resultado diferente.
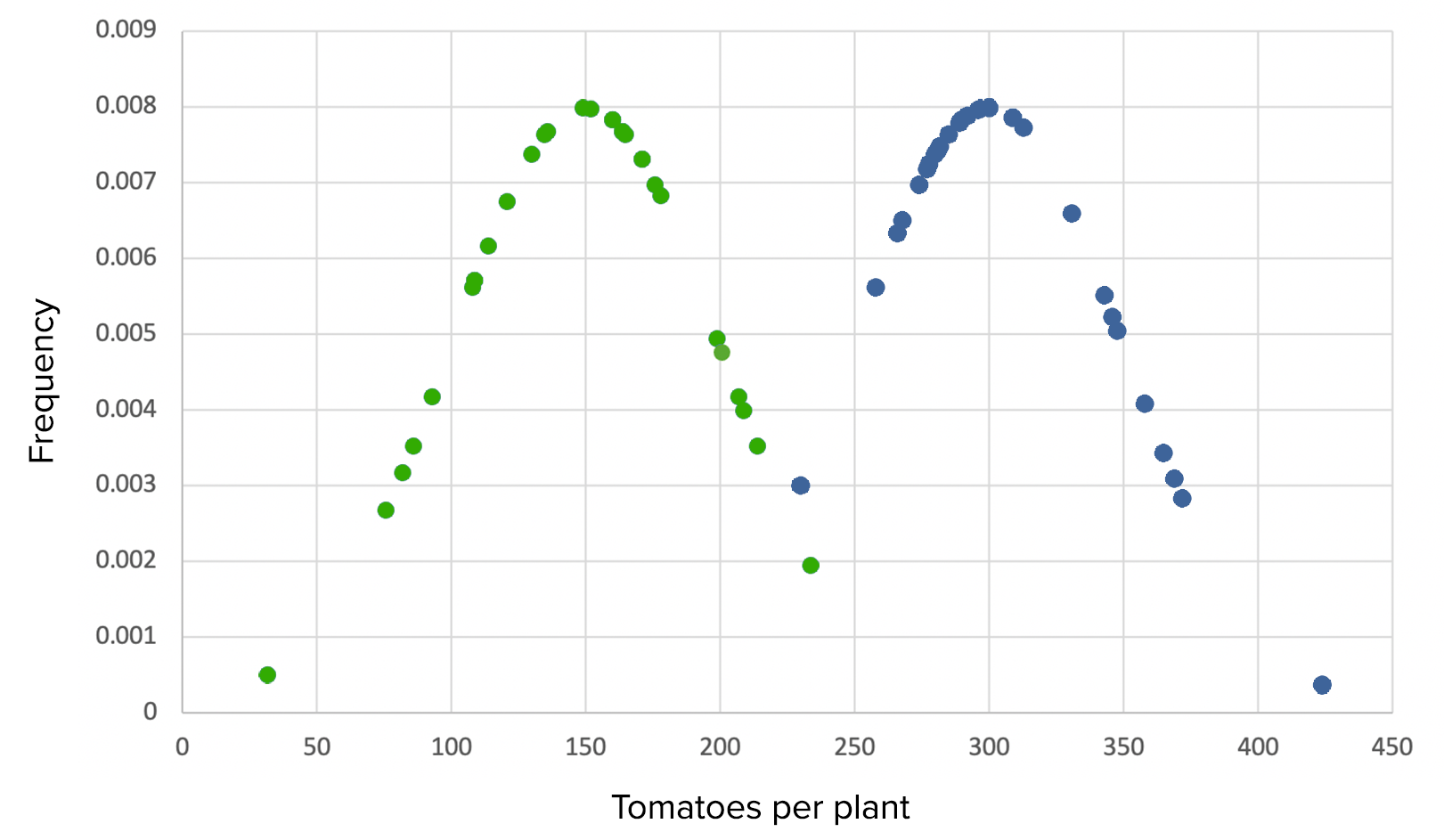
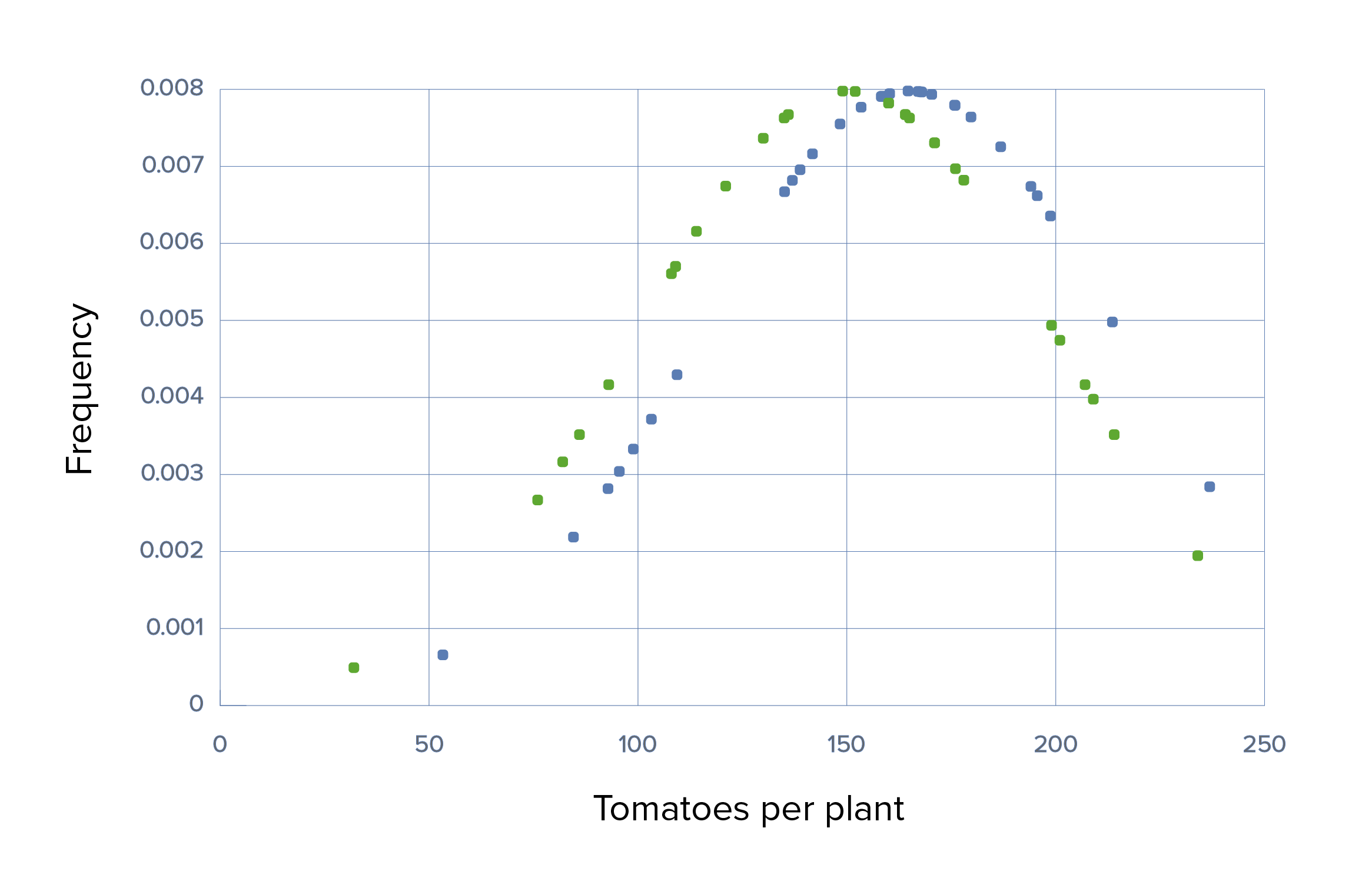
Ensaio 2 com tamanhos de amostra pequenos:
A experiência acabaria com DP grandes com muito menos sementes também, e quase todos os testesTestesGonadal Hormones t dariam corretamente um p-value significativo (pequeno).
Ensaio 2, cenário 1: Gráfico que demonstra o uso de Grow-A-Lot com tamanho de efeito grande, DPs grandes, médias de 150 versus 300, DP de 50 em cada e tamanhos de amostra pequenos de 30
Verde: grupo de controlo Azul: grupo experimental
Ainda se pode ver uma diferença significativa entre os grupos, tanto observando o gráfico quanto por testes estatísticos, devido ao grande efeito do tamanho. O resultado é significativo com p < 0,05, então a hipótese nula é rejeitada.
É usado um fertilizante diferente (fertilizante “Grow-A-Little”) que tem um efeito muito menor, produzindo uma média de apenas 10 tomates extra por planta. Haverá uma maior sobreposição de produção de tomate por planta entre os grupos experimental e de controlo, o que pode ser detetado apenas usando tamanhos de amostra maiores.
Ensaio 3 com tamanhos de amostra grandes e DPs grandes:
Os tamanhos da amostra são suficientemente grandes para contrabalançar o ES pequeno, tornando a diferença estatisticamente significativa num p-value < 0,05. Observe que, embora a diferença seja estatisticamente significativa, esta pequena diferença pode não ter significância prática ou relevante para o agricultor.
Ensaio 3, cenário 2: Gráfico que demonstra o uso de Grow-A-Little com tamanho de efeito pequeno, DPs grandes, médias de 150 versus 165, DP de 50 em cada e tamanhos de amostra grandes de 100
Verde: grupo de controlo Azul: grupo experimental.
A diferença é estatisticamente significativa num p-value de < 0,05 porque os tamanhos das amostras eram suficientemente grandes para neutralizar o pequeno tamanho do efeito. Note que, mesmo sendo estatisticamente significativa, a pequena diferença pode não ter significância prática ou relevante para o agricultor.
Ensaio 4 com tamanhos de amostra pequenos e DPs grandes:
Devido ao pequeno tamanho da amostra, não é encontrada nenhuma diferença estatisticamente significativa num p-value < 0,05. Portanto, a hipótese nula não pode ser rejeitada porque o estudo não teve um efeito ou tamanho de amostra suficientemente grande.
Ensaio 4, cenário 2: Gráfico que demonstra o uso de Grow-A-Little com tamanho de efeito pequeno, DPs grandes, médias de 150 versus 165, DP de 50 em cada e tamanhos de amostra pequenos de 30
Verde: grupo de controlo Azul: grupo experimental
Não é revelada nenhuma diferença estatisticamente significativa num p-value de < 0,05, então a hipótese nula não pode ser rejeitada porque o ensaio não teve um tamanho de efeito grande o suficiente ou tamanhos de amostra grandes o suficiente.
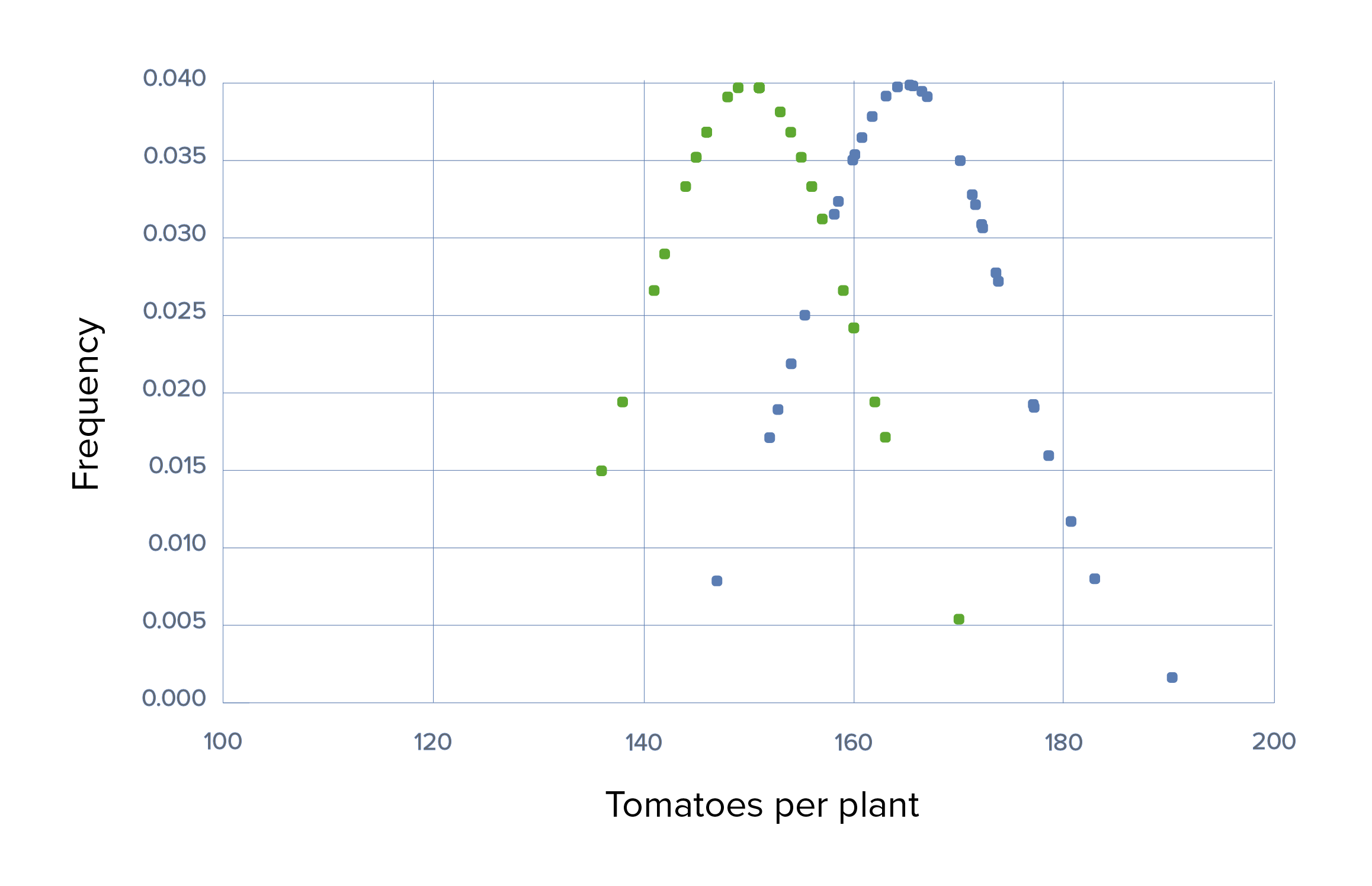
Ensaio 5 com tamanhos de amostra pequenos e DPs pequenos:
Devido a um DP pequeno, a diferença é estatisticamente significativa num p-value de 0,05. O DP geralmente é um parâmetro fixo numa população e não pode ser alterado, mas o mesmo resultado pode ser efetivamente obtido aumentando o tamanho da amostra. O aumento diminui o impacto de um valor de DP grande mas fixo, permitindo detetar diferenças menores entre os grupos testados.
Ensaio 5, cenário 2: Gráfico que demonstra o uso de Grow-A-Little com tamanho de efeito pequeno, DPs pequenos de 10 em cada, médias de 150 versus 165 e tamanhos de amostra pequenos de 30
Verde: grupo de controlo Azul: grupo experimental
A diferença agora é estatisticamente significativa num p-value de 0,05 por causa dos pequenos DPs.
Os investigadores envolvidos na conceção de um ensaio clínico aleatorizado escolheram um tamanho de amostra que teria 90% de poder de detetar uma diferença de 20% entre os grupos de controlo e experimental, com nível de significância (bilateral) de 5%.
Questão 1
Se, na realidade, não houver diferença nas médias, qual é a chance de o estudo encontrar uma diferença estatisticamente significativa? Como se chama esse erro?
Resposta: Um erro tipo I (falso positivo). Esta é apenas uma questão de terminologia e é típica do tipo de questão presente nas provas de exame, com a potência inserida como fator de distração. Consulte o primeiro gráfico multicolorido acima: se não houver diferença entre os 2 grupos, haverá apenas 1 curva normal, com o ponto de corte alfa descrevendo os falsos positivos; assim, a chance de encontrar uma diferença estatisticamente significativa é de 5%, gerando um erro tipo I (falso positivo), pois qualquer sujeito com valor na área alfa pertence à mesma população.
Questão 2
A potência aumenta/diminui/não muda se o beta for diminuído?
Resposta: A potência aumenta se o beta for diminuído, pois a potência = 1 – beta. Consulte o primeiro gráfico multicolorido.
Questão 3
A potência aumenta/diminui/não muda se o alfa for aumentado?
Resposta: A potência aumenta se o alfa for aumentado, o que aumenta a probabilidade de falsos positivos; assim, aumentar o alfa não é uma forma preferencial de aumentar a potência. Consulte o primeiro gráfico multicolorido para ver a relação entre alfa e potência. Num exame final, é frequentemente usada uma tabela de contingência 2 x 2 de realidade/verdade versus resultados de estudo/teste para enquadrar esta questão. É importante entender como calcular os erros tipo I e tipo II.
Pergunta 4
A potência aumenta/diminui/não muda se a diferença entre a média do grupo experimental e a do grupo de controlo aumentar?
Resposta: A potência aumenta aumentando a diferença das médias, que é outra forma de aumentar o ES, pois há menos sobreposição entre as 2 distribuições. Veja o primeiro gráfico multicolorido.
Pergunta 5
O beta aumenta/diminui/não muda se a diferença entre a média do grupo experimental e a do grupo de controlo aumentar?
Resposta: O beta diminui se a diferença das médias aumenta, pois há menos sobreposição entre as 2 populações. Veja o primeiro gráfico multicolorido.
Referências
Clinical tools and calculators for medical professionals—ClinCalc. Retrieved July 20, 2026, from https://clincalc.com/
Brant, R. (n.d.). Inference for means: Comparing two independent samples [Statistical calculator]. University of British Columbia, Department of Statistics. Retrieved July 20, 2026, from https://www.stat.ubc.ca/~rollin/stats/ssize/n2.html
Otte, W.M., Tijdink, J.K., Weerheim, P.L., Lamberink, H.J., Vinkers, C.H. (2018). Adequate statistical power in clinical trials is associated with the combination of a male first author and a female last author. eLife, 7:e34412. Retrieved July 20, 2026, from https://doi.org/10.7554/eLife.34412
Bland, M. (2015). An Introduction to Medical Statistics. 4th ed., pp. 295–304.
Ellis, P.D. (2010). The Essential Guide to Effect Sizes. Statistical Power, Meta-Analysis, and the Interpretation of Research Results. Pp. 46–86.
Walters, S.J., Campbell, M.J., Machin, D. (2020). Medical Statistics, A Textbook for the Health Sciences. 5th ed, pp. 40–48, 99–133.
Citrome, L., Ketter, T.A. (2013). When does a difference make a difference? Interpretation of number needed to treat, number needed to harm, and likelihood to be helped or harmed. International Journal of Clinical Practice, 67(5):407–41. Retrieved July 20, 2026, from https://doi.org/https://doi.org/10.1111/ijcp.12142
Ioannidis, J.P., Greenland, S., Hlatky, M.A., et al. (2014). Increasing value and reducing waste in research design, conduct, and analysis. Lancet, 383(9912):166–175.
Allen, J.C. (2011). Sample size calculation for two independent groups: A useful rule of thumb. Proceedings of Singapore Healthcare, 20(2):138–140. Retrieved July 20, 2026, from https://doi.org/10.1177/201010581102000213
¡Crea tu cuenta gratis o inicia una sesión para seguir leyendo!
A Lecturio Medical complementa o teu estudo através de métodos de ensino baseados em evidência, vídeos de palestras, perguntas e muito mais – tudo combinado num só lugar e fácil de usar.
User Reviews
Details
×
Obtenha Premium para testar os seus conhecimentos
Lecturio Premium dá-lhe acesso total a todos os conteúdos e características
Obtenha Premium para ver todos os vídeos
Verifique agora o seu e-mail para obter um teste gratuito.
Crie uma conta gratuita para testar os seus conhecimentos
Lecturio Premium dá-lhe acesso total a todos os conteúdos e características - incluindo o Qbank de Lecturio com perguntas actualizadas ao estilo do board-.