La potencia estadística es la probabilidad de detectar un efecto cuando ese efecto existe realmente enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum la población. EnENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum igualdad de condiciones, una prueba basada enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum una muestra grande tiene más potencia estadística que una prueba con una muestra pequeña. También hay formas de aumentar la potencia sin aumentar el tamaño de la muestra. La mayoría de losLOSNeisseria estudios publicados tienen una baja potencia estadística, lo que puede llevar a una grave interpretación errónea de losLOSNeisseria resultados.
La potencia estadística se expresa de 3 maneras diferentes:
Potencia estadística es la probabilidad de encontrar significancia estadística si la hipótesis alternativa es verdadera.
La potencia estadística es la probabilidad de rechazar correctamente una hipótesis nula falsa, donde la hipótesis nula es la hipótesis que propone que no hay diferencias significativas entre poblaciones específicas (e.g., grupos de control frente a grupos experimentales).
Potencia estadística = 1 – beta (β), donde β = errorErrorRefers to any act of commission (doing something wrong) or omission (failing to do something right) that exposes patients to potentially hazardous situations.Disclosure of Information de tipo II (falso negativo), equivalente a 1 – sensibilidad. Cuanto más potente sea un estudio clínico experimental, más fácilmente detectará un efecto del tratamiento cuando realmente exista.
Baja potencia estadística
Menos del 13% de losLOSNeisseria 31 873 ensayos clínicos publicados entre 1974 y 2017 tenían una potencia estadística adecuada. Un estudio con una potencia estadística baja significa que losLOSNeisseria resultados de la prueba son cuestionables y plantea problemas potencialmente graves, entre ellos:
Una menor probabilidad de detectar un efecto verdadero, genuino y significativo enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum la población estudiada, lo que puede bloquear la realización de más estudios
Menor probabilidad de que un resultado estadísticamente significativo refleje un efecto verdadero (e.g., más falsos positivos)
Sobreestimación del verdadero tamaño del efecto del tratamiento
Baja reproducibilidad
Posible violación de losLOSNeisseria principios éticos:
LosLOSNeisseria pacientes y voluntarios sanos siguen participando enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum investigaciones que pueden tener un valor clínico limitado.
Sacrificio innecesario de animales de investigación
Desorden enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum la interpretación de estudios con muestras pequeñas que utilizan la misma metodología, pero que producen resultados contradictorios
Demasiada potencia estadística: estudios con exceso de potencia
LosLOSNeisseria estudios con demasiada potencia estadística, también llamados “estudios con exceso de potencia”, suelen ser problemáticos por las siguientes razones:
Pueden ser engañosos, ya que tienen el potencial de mostrar una significancia estadística y también diferencias clínicas sin importancia/irrelevantes
Resultan enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum un desperdicio de recursos
Pueden ser poco éticos debido a la participación de seres humanos y/o animales de laboratorio enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum experimentos innecesarios
Características
La potencia estadística solo tiene relevancia cuando se puede rechazar la hipótesis nula, y viene determinada por las siguientes variables:
Alfa (α)
Beta (β)
Desviación estándar de la población
Tamaño de la muestra
Tamaño del efecto del tratamiento
Alfa
Alfa es la probabilidad de dar un resultado positivo enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum una prueba diagnóstica entre quienes no tienen la enfermedad, lo que provoca un errorErrorRefers to any act of commission (doing something wrong) or omission (failing to do something right) that exposes patients to potentially hazardous situations.Disclosure of Information de tipo I o un “falso positivo”.
Alfa = la probabilidad de rechazar la hipótesis nula entre aquellos que satisfacen la hipótesis nula
Alfa = 1 – especificidad = “valor p” = “el nivel de significancia”
A un nivel de significancia (alfa) de 0,05, el 5% de las muestras puede mostrar una diferencia falsamente significativa debida simplemente alALAmyloidosis azar.
La mayoría de losLOSNeisseria estudios utilizan un límite alfa del 5% (0,05).
Beta
Beta es la posibilidad de dar un resultado negativo enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum una prueba diagnóstica entre losLOSNeisseria que padecen la enfermedad, lo que provoca un errorErrorRefers to any act of commission (doing something wrong) or omission (failing to do something right) that exposes patients to potentially hazardous situations.Disclosure of Information de tipo II o un “falso negativo”.
Beta = la probabilidad de aceptar la hipótesis nula entre aquellos que no satisfacen la hipótesis negativa
Beta se relaciona de manera inversa con la potencia estadística del estudio (potencia estadística = 1 – β).
Con un nivel de beta de 0,2, el 20% de las muestras pueden pasar por alto una verdadera diferencia significativa.
La mayoría de losLOSNeisseria estudios utilizan un límite beta del 20% (0,2).
A diferencia de alfa, hay un valor diferente de beta para cada valor medio diferente de la hipótesis alternativa; por lo tanto, beta depende tanto del valor de corte establecido por alfa como de la media de la hipótesis alternativa.
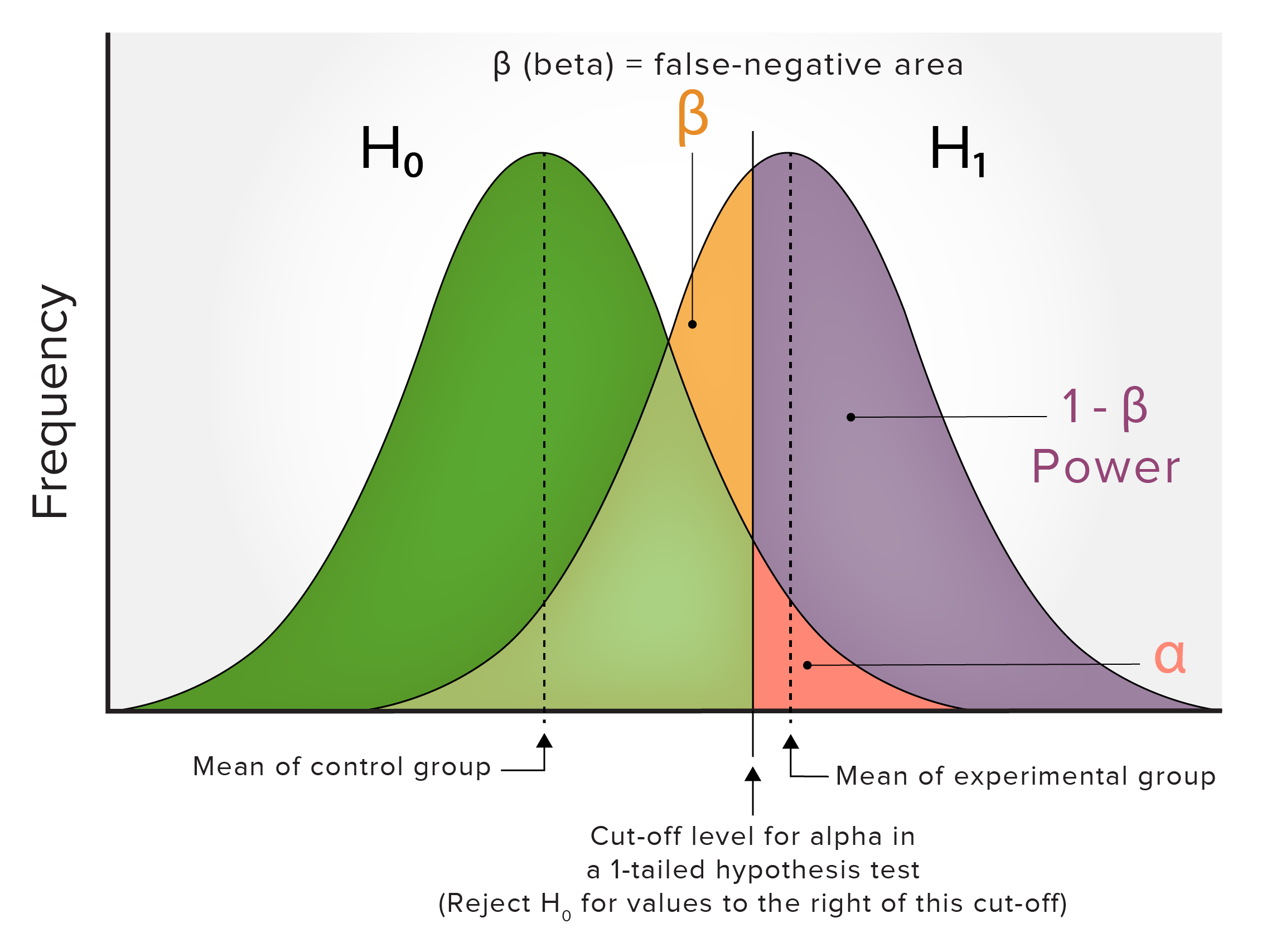
Relación entre alfa y beta
La relación entre alfa y beta suele representarse enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum gráficos que muestran:
2 poblaciones o distribuciones normalizadas:
Un grupo de control
Un grupo experimental (que puede tener una media diferente y estadísticamente significativa)
H0: la hipótesis nula, que afirma que solo hay 1 media verdadera (del grupo de control) y que cualquier variación encontrada enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum la muestra/grupo experimental solo se debe a una variación aleatoria normal enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum la distribución
H1: la hipótesis alternativa, que es un enunciado que contradice directamente la hipótesis nula alALAmyloidosis afirmar que el valor real de un parámetro de la población es menor o mayor que el valor establecido enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum la hipótesis nula.
Alfa (α): el área de falsos positivos (generalmente se muestra como una prueba de hipótesis de 2 colas)
Relación entre alfa y beta: Este es un gráfico de dos poblaciones o distribuciones normalizadas de un grupo de control (verde) y un grupo experimental (púrpura) con una media diferente estadísticamente significativa. Lea el texto para la explicación de los símbolos utilizados.
Existe una relación inversa entre alfa y beta. Si beta está disminuida:
El área de alfa aumentaría.
El número de falsos negativos o errores de tipo II disminuiría.
El número de falsos positivos o errores de tipo I aumentaría.
La relación inversa de alfa y beta también se puede apreciar enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum una tabla de contingencia 2 x 2 que compara losLOSNeisseria resultados positivos y negativos de la realidad frente a un estudio.
Resultados positivos reales
Resultados negativos reales
Resultados positivos del estudio
Verdaderos positivos (potencia, 1 – β)
Falsos positivos (errorErrorRefers to any act of commission (doing something wrong) or omission (failing to do something right) that exposes patients to potentially hazardous situations.Disclosure of Information de tipo I, α)
Resultados negativos del estudio
Falsos negativos (errorErrorRefers to any act of commission (doing something wrong) or omission (failing to do something right) that exposes patients to potentially hazardous situations.Disclosure of Information de tipo II, β)
Verdaderos negativos
Desviación estándar de la población
La desviación estándar es una medida de la cantidad de variación o dispersión de un conjunto de valores enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum relación con la media.
Se calcula como la raíz cuadrada de la varianza, que es la media de las diferencias alALAmyloidosis cuadrado con respecto a la media.
Cuanto mayor sea la desviación estándar, más pacientes se necesitan enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum una muestra para demostrar una diferencia estadísticamente significativa.
Tamaño de la muestra
El tamaño de la muestra es el número de observaciones de una muestra.
Una muestra más grande representará mejor a la población, por lo que la potencia de la prueba aumentará de forma natural.
Parámetro más utilizado para aumentar la potencia de un estudio
Para una prueba t de 2 muestras y 2 colas con un nivel alfa de 0,05, la sencilla fórmula que aparece a continuación dará un tamaño de muestra aproximado necesario para tener una potencia estadística del 80% (beta = 0,2):
$$ n = \frac{16s^{2}}{d^{2}} $$
donde n = tamaño de cada muestra, s = desviación estándar (se supone que es la misma enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum cada grupo), y d = diferencia a detectar. La mnemotecnia, sugerida por el creador de la fórmula, Robert Lehr, es “16 s-squared over d-squared.” (16 s-cuadrado sobre d-cuadrado). (Nota: “s-cuadrado” también se conoce como varianza).
Ejemplos:
Encuentre el número aproximado de pacientes con hipertensión enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum estadio I (sistólica 130–139 mm Hg o diastólica 80–89 mm Hg) necesario para proporcionar una potencia del 80% para detectar una diferencia de 15 mm Hg enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema NodosumlosLOSNeisseria tratamientos de presión arterial diastólica A y B utilizando una prueba t de 2 muestras, 2 colas, alfa = 0,05, dado que la desviación estándar esperada para cada grupo es de 15 mm Hg. Respuesta: El tamaño aproximado de la muestra n = “16 s-cuadrado sobre d-cuadrado” = 16 x 152/152= 16 x 225/225 = 16 personas enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum cada grupo. Tenga enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum cuenta que uno de losLOSNeisseria “tratamientos” suele establecerse como grupo de control (no tratado).
De otra forma: enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum 2 grupos con 16 pacientes cada uno que sufrían de hipertensión enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum estadio I, se encontró una diferencia de 15 mm Hg después de que losLOSNeisseria pacientes de cada grupo fueran tratados con 2 tratamientos diferentes. Si alfa = 0,05 y beta = 0,2, ¿el tamaño de la muestra era suficiente para detectar una diferencia significativa? Respuesta: n = 16 x 152/152= 16 personas enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum cada grupo. Así que, sí, el tamaño de la muestra era suficiente.
EnENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum la pregunta 1, ¿cuál sería el número aproximado de pacientes necesarios, si el investigador quisiera detectar una diferencia de 7,5 mm Hg enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum lugar de una diferencia de 15 mm Hg, con todos losLOSNeisseria demás parámetros iguales? Respuesta: n = 16 x 152/7,52 = 16 x 225/56,25 = 64 personas enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum cada grupo EnENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum este último ejemplo, obsérvese que para detectar la mitad de la diferencia se necesita 4 veces el tamaño de la muestra, lo que se haceHACEAltitude Sickness evidente con la simple fórmula.
Tamaño del efecto del tratamiento
El tamaño del efecto es la diferencia media estandarizada entre 2 grupos, que es análoga a la “puntuación Z” de una distribución normal estándar.
Si la diferencia entre losLOSNeisseria 2 tratamientos es pequeña, se necesitarán más pacientes para detectar una diferencia.
Otras situaciones que tienen tamaño del efecto:
La correlación entre 2 variables
El coeficiente de regresión enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum un cálculo de regresión
El riesgo de un evento concreto (e.g., un accidente cerebrovascular)
Cálculo del tamaño del efecto con la d de Cohen:
La d de Cohen es el método más común (pero imperfecto) para calcular el tamaño del efecto. La d de Cohen = la diferencia estimada enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum las medias/(desviaciones estándar estimadas agrupadas), donde:
$$ {SD = \sqrt{\frac{(SD1^{2} + SD2^{2})}{2}}} $$
Si las desviaciones estándar son iguales enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum cada grupo, entonces d = diferencias medias/desviación estándar. Por ejemplo, si la diferencia es de 150 y la desviación estándar es de 50, entonces d = 150/50 = 3, que es un tamaño del efecto grande.
Interpretación de la d de Cohen:
Tamaño del efecto pequeño: Si d = 0,2, la puntuación o valor del sujeto medio del grupo experimental está 0,2 desviaciones estándar por encima del valor del sujeto medio del grupo de control, superando losLOSNeisseria valores del 58% del grupo de control.
Tamaño del efecto medio: Si d = 0,5, el valor del sujeto medio del grupo experimental está 0,5 desviaciones estándar por encima del valor del sujeto medio del grupo de control, superando losLOSNeisseria valores del 69% del grupo de control.
Tamaño del efecto grande: Si d = 0,8, el valor del sujeto medio está 0,8 desviaciones estándar por encima del valor del sujeto medio del grupo de control, superando losLOSNeisseria valores del 79% del grupo de control.
Resumen de características
EnENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum resumen, la potencia estadística tenderá a ser mayor cuando:
El tamaño del efecto (diferencia entre grupos) es grande.
El tamaño de la muestra es grande.
Las desviaciones estándar de las poblaciones son pequeñas.
El nivel de significancia alfa es mayor (e.g., 0,05 enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum lugar de 0,01).
El corte beta es bajo (e.g., 0,1 frente a 0,2).
Se utiliza una prueba de 1 cola enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum lugar de una prueba de 2 colas.
Sin embargo, la hipótesis direccional no puede detectar una diferencia enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum la dirección opuesta.
Esta prueba se utiliza raramente.
Errores comunes
Rechazar una hipótesis nula (e.g., hay una diferencia significativa) sin considerar la importancia práctica/clínica del hallazgo del estudio
Aceptar una hipótesis nula (e.g., no rechazar una hipótesis nula) cuando un resultado NO es estadísticamente significativo, sin tener enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum cuenta la potencia
Ser convencido por un estudio de investigación con poca potencia
No realizar un análisis de potencia/cálculo del tamaño de la muestra
No corregir la inferencia múltiple alALAmyloidosis calcular la potencia:
La inferencia múltiple es el proceso de realizar más de 1 prueba de inferencia estadística enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum el mismo conjunto de datos.
La realización de varias pruebas sobre el mismo conjunto de datos enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum la misma fase de análisis aumenta la posibilidad de obtener alALAmyloidosis menos 1 resultado no válido.
Utilizar tamaños de efecto estandarizados (e.g., losLOSNeisseria tamaños de efecto pequeños, medianos y grandes de la d de Cohen) enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum lugar de considerar losLOSNeisseria detalles del propio diseño experimental. A veces, un experimento puede tener un resultado pequeño de la d de Cohen pero ser un experimento mejor.
Confundir la potencia retrospectiva (calculada después de recoger losLOSNeisseria datos) y la potencia prospectiva
Análisis
Un análisis de potencia responde a 2 grandes preguntas:
¿Qué cantidad de potencia estadística se considera adecuada?
¿Qué tamaño de muestra se necesita?
¿Qué potencia estadística se considera adecuada?
El nivel mínimo tradicional de potencia es el 80% (o 0,80), alALAmyloidosis igual que el valor arbitrario del 5% (o 0,05) es el límite mínimo tradicional de alfa para fijar el valor p enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum 0,05.
Un nivel de potencia del 80% significa que hay un 20% de probabilidad de encontrar un errorErrorRefers to any act of commission (doing something wrong) or omission (failing to do something right) that exposes patients to potentially hazardous situations.Disclosure of Information de tipo II (falso negativo).
Este nivel aceptable del 20% de tener errores de tipo II es 4 veces mayor que la probabilidad del 5% de encontrar un errorErrorRefers to any act of commission (doing something wrong) or omission (failing to do something right) that exposes patients to potentially hazardous situations.Disclosure of Information de tipo I (falso positivo) para el valor estándar del nivel de significancia.
Sería mucho mejor tener un nivel de potencia del 90%. Aunque se necesitan más recursos, hay que tener enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum cuenta que se necesitaría aún más para volver a realizar el estudio más adelante.
¿Qué tamaño de muestra se necesita?
Una muestra lo suficientemente grande como para detectar un efecto de importancia científica práctica que garantice una probabilidad lo suficientemente alta como para rechazar una hipótesis nula falsa
El análisis de potencia debe realizarse antes de iniciar un experimento.
No se puede seguir añadiendo sujetos a un experimento terminado que tenía un valor p casi significativo.
Esta práctica está mal vista y constituye lo que se llama “p-hacking” o “data-dredging” (términos enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum inglés para “manipulación de la p” y “cavar datos” respectivamente).
Calcular el tamaño adecuado de la muestra para una prueba t de muestras independientes:
Estimar (mediante un estudio piloto o datos históricos) las medias poblacionales de losLOSNeisseria 2 grupos o la diferencia entre las medias, que debe ser el tamaño del efecto más pequeño que tenga interés científico.
Estimar (mediante un estudio piloto o datos históricos) las desviaciones estándar de la población de losLOSNeisseria 2 grupos.
Decida qué niveles de alfa (e.g., 0,05) y beta (e.g., 0,2) se desean.
Introduzca estos valores (alfa, beta, las 2 medias estimadas y la desviación estándar estimada conjunta) enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum una calculadora de potencia estadistica enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum línea de buena reputación para obtener el tamaño de la muestra.
LosLOSNeisseria cálculos son algo complejos y siempre se hacen con un ordenador.
Se puede calcular el tamaño aproximado de la muestra mediante la fórmula n =16s2/d2, como se haHAHemolytic anemia (HA) is the term given to a large group of anemias that are caused by the premature destruction/hemolysis of circulating red blood cells (RBCs). Hemolysis can occur within (intravascular hemolysis) or outside the blood vessels (extravascular hemolysis).Hemolytic Anemia comentado anteriormente.
Ejemplos de Cálculos y Análisis de Potencia Estadística
Escenario 1
Se hizo una prueba con un nuevo fertilizante llamado “Grow-A-Lot”, se le dio a un agricultor de tomates para determinar si se producían más tomates por planta con el nuevo fertilizante enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum comparación con las plantas no fertilizadas. El agricultor escogió 200 semillas de tomate de un cubo de sus semillas habituales y las dividió enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum dos grupos:
Un grupo de 100 semillas que no recibieron fertilizante (el grupo de control)
Un grupo de 100 semillas que recibieron fertilizante (el grupo experimental)
La hipótesis nula es que ambos grupos de plantas producirían el mismo número de tomates por planta, mientras que la hipótesis alternativa sería que las plantas que reciben el fertilizante producirían un número diferente de tomates.
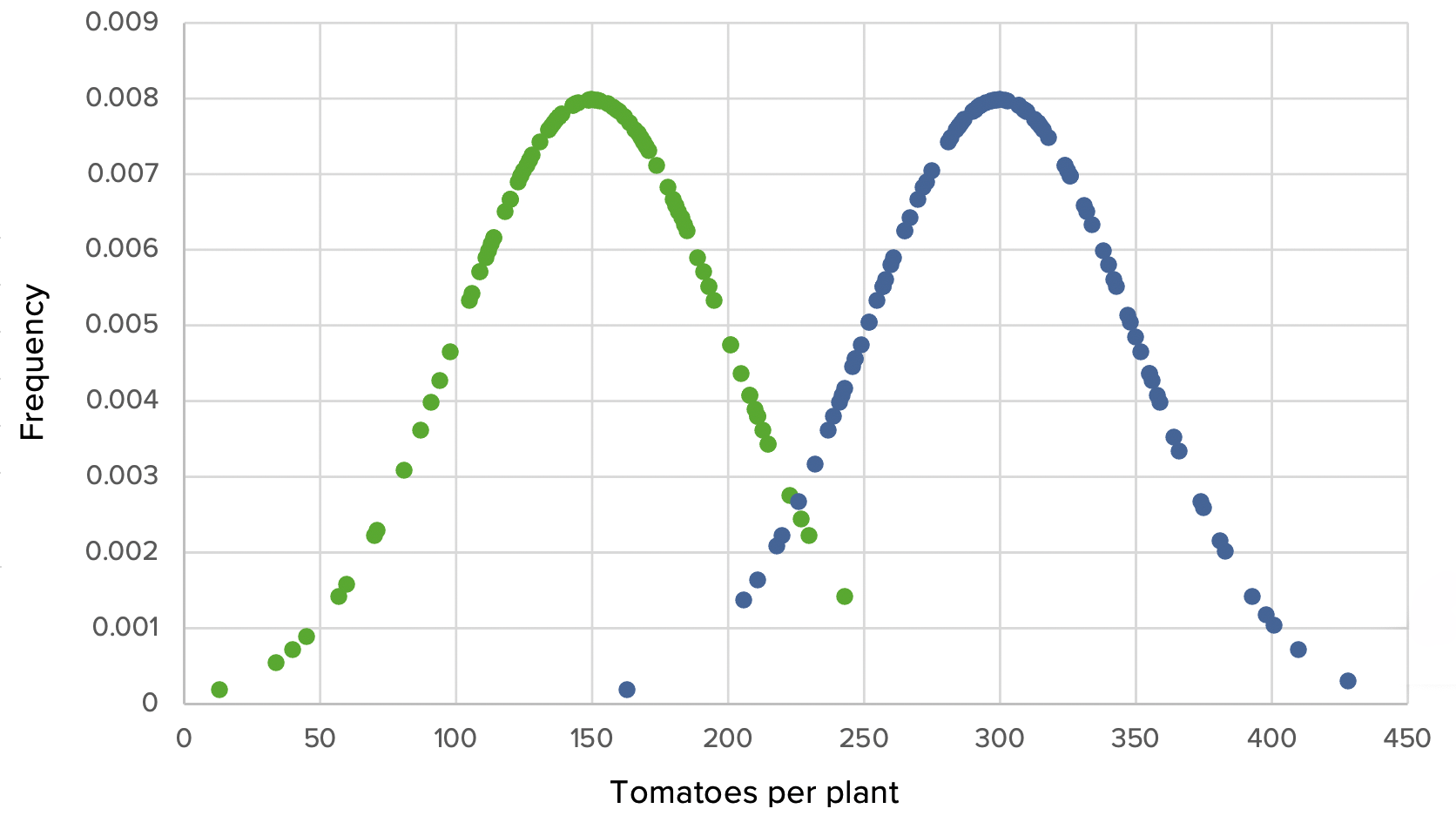
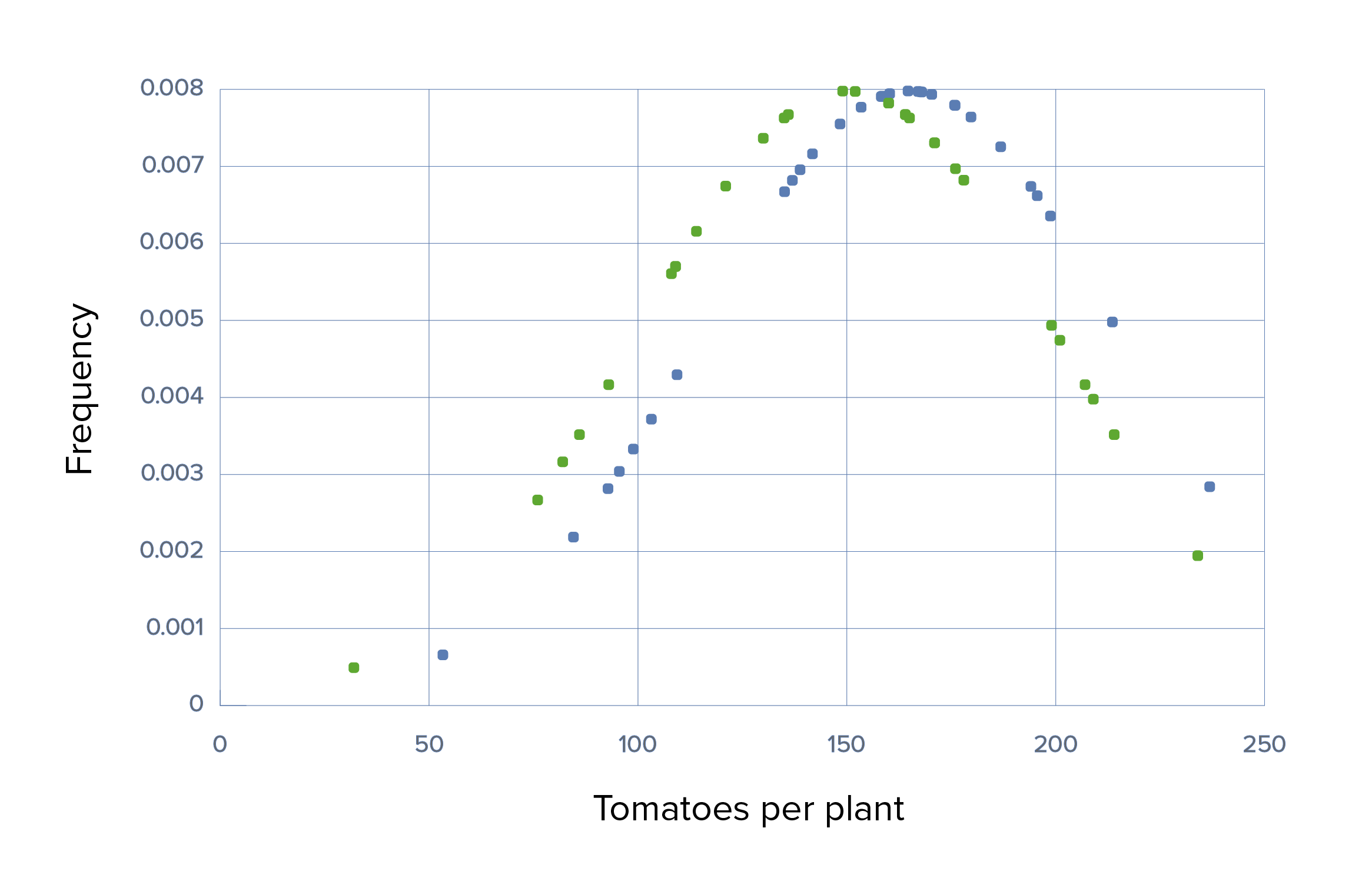
Ensayo 1 con muestras de gran tamaño:
El grupo fertilizado produjo una media del doble de tomates (300) que el grupo de control (150). También hay un pequeño solapamiento, ya que algunas plantas del grupo de control superaron a las demás de su grupo, mientras que algunas plantas del grupo experimental tuvieron un rendimiento inferior. Basta con echar un vistazo alALAmyloidosis gráfico para darse cuenta de que hay una diferencia evidente, pero se realizó una prueba t para confirmar que la diferencia era estadísticamente significativa, con un valor p muy pequeño.
Ensayo 1, escenario 1: gráfico que demuestra el uso de Grow-A-Lot con un gran tamaño del efecto, grandes *SD, media de 150 frente a 300, *SD de 50 en cada una, y grandes tamaños de muestra de 100
Verde: grupo de control Azul: grupo experimental
Las 100 plantas del grupo de control dieron lugar a una media de 150 tomates por planta. Mientras que las 100 plantas que recibieron fertilizante produjeron significativamente más tomates, con una media de 300 tomates por planta. El resultado es significativo con un valor p de < 0,05, por lo que se rechaza la hipótesis nula.
Aunque el experimento se repitiera 1 000 veces, sería extremadamente improbable que el agricultor eligiera alALAmyloidosis azar un conjunto diferente de semillas de la región de solapamiento para obtener un resultado diferente. El tamaño del efecto grande por sí solo da a este ensayo una gran cantidad de potencia estadística porque sería extremadamente improbable que la repetición del muestreo produjera un resultado diferente.
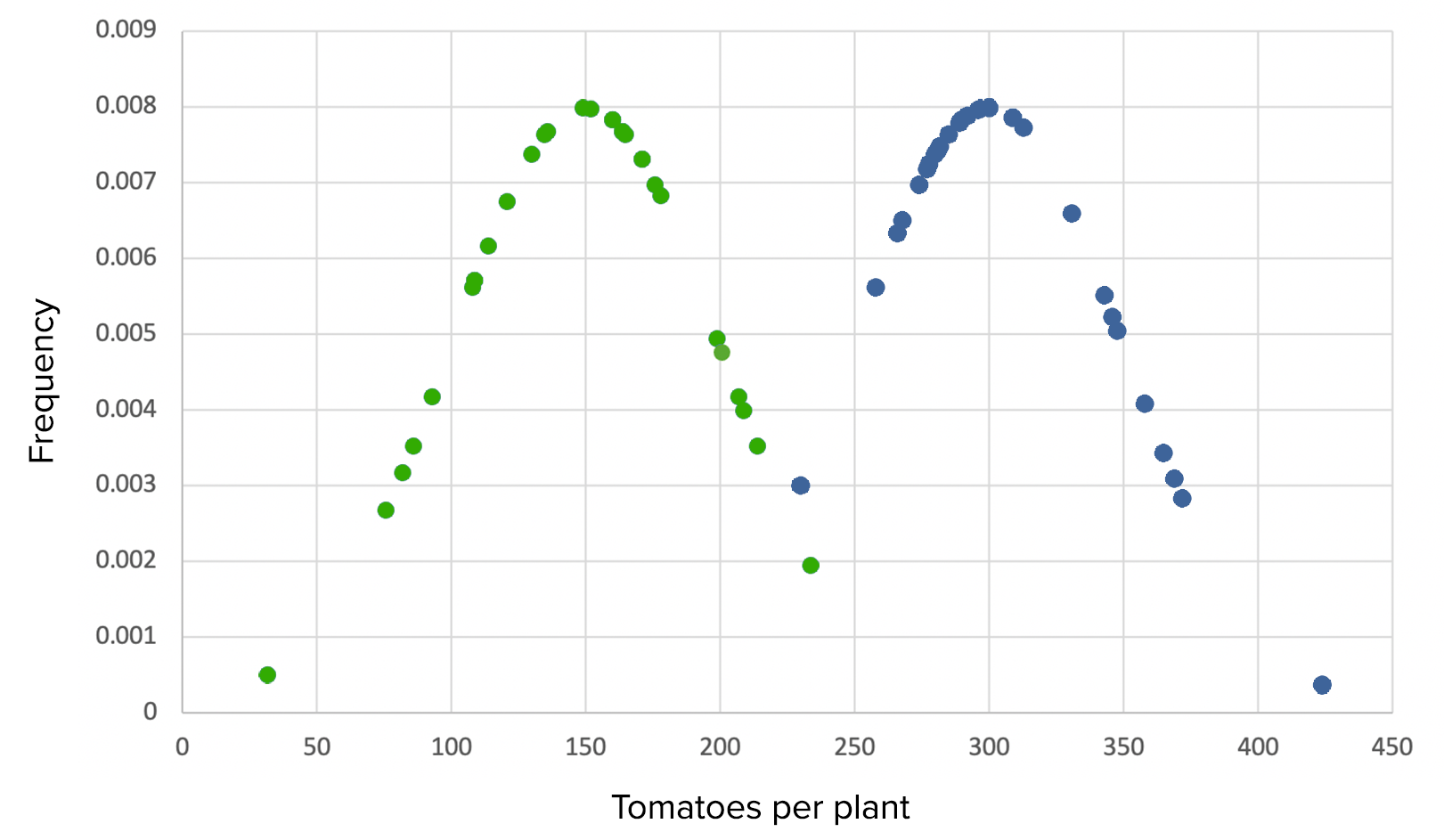
Ensayo 2 con tamaños de muestra pequeños:
El experimento conservaría una gran potencia estadística con muchas menos semillas también, y casi todas las pruebas t darían correctamente un valor p significativo (pequeño).
Ensayo 2, escenario 1: gráfico que demuestra el uso de Grow-A-Lot con un gran tamaño del efecto, grandes *SD, media de 150 frente a 300, *SD de 50 en cada una, y tamaños de muestra pequeños de 30
Verde: grupo de control Azul: grupo experimental
Todavía se puede observar una diferencia significativa entre los grupos, tanto a simple vista como mediante pruebas estadísticas, debido al gran tamaño del efecto. El resultado es significativo a p < 0,05, por lo que se rechaza la hipótesis nula.
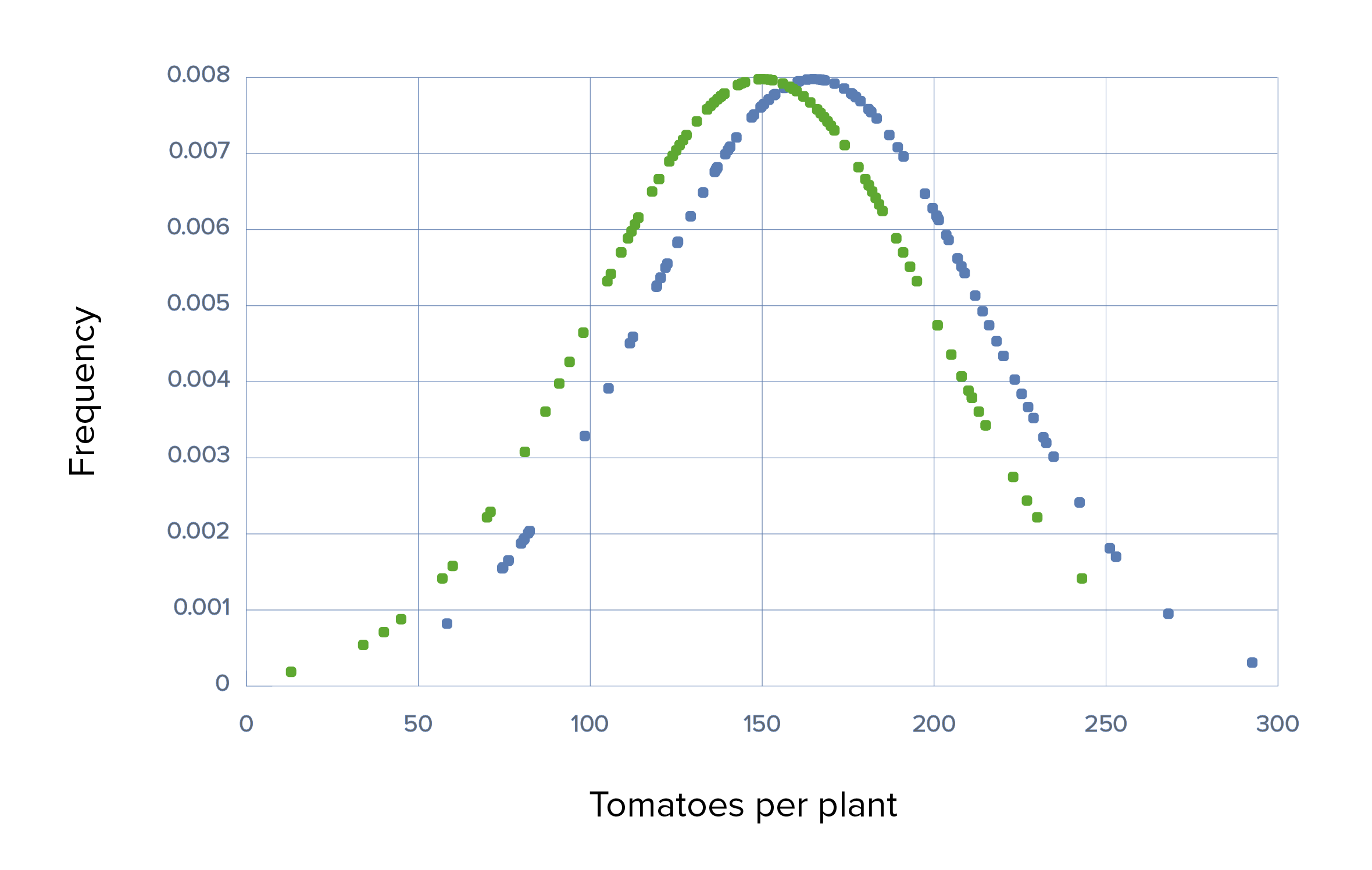
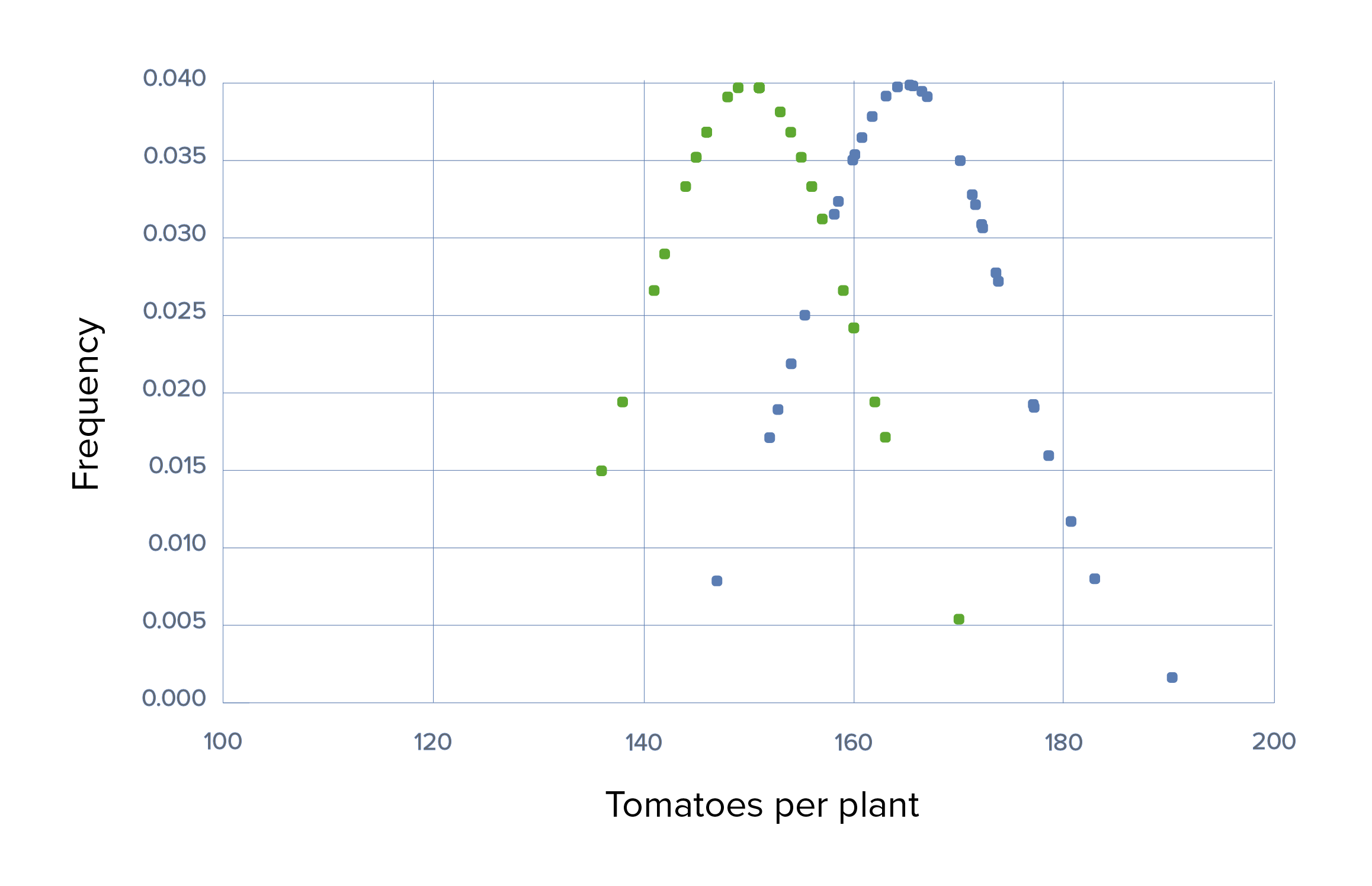
Se utiliza un fertilizante diferente (fertilizante “Grow-A-Little”) que tiene un efecto mucho menor, produciendo una media de solo 10 tomates más por planta. Habrá un mayor solapamiento de la producción de tomate por planta entre losLOSNeisseria grupos experimental y de control, que solo podrá detectarse utilizando tamaños de muestra mayores.
Ensayo 3 con tamaños de muestra grandes y grandes desviaciones estándar:
El tamaño de las muestras es lo suficientemente grande como para contrarrestar el tamaño del efecto pequeño, lo que haceHACEAltitude Sickness que la diferencia sea estadísticamente significativa con un valor p < 0,05. Obsérvese que, aunque la diferencia es estadísticamente significativa, esta pequeña diferencia puede no tener una importancia práctica o relevante para el agricultor.
Ensayo 3, escenario 2: gráfico que demuestra el uso de Grow-A-Little con un tamaño del efecto pequeño, *SD grandes, media de 150 frente a 165, *SD de 50 en cada uno, y tamaño de muestra grande de 100
Verde: grupo de control Azul: grupo experimental.
La diferencia es estadísticamente significativa con un valor p de < 0,05 porque el tamaño de las muestras era lo suficientemente grande como para contrarrestar el pequeño tamaño del efecto. Hay que tener en cuenta que, aunque sea estadísticamente significativa, la pequeña diferencia puede no tener una importancia práctica o relevante para el agricultor.
Ensayo 4 con tamaños de muestra pequeños y grandes desviaciones estándar:
Debido alALAmyloidosis pequeño tamaño de las muestras, no se encuentran diferencias estadísticamente significativas con un valor p < 0,05. Por lo tanto, no se puede rechazar la hipótesis nula porque el ensayo no tenía un efecto o tamaño de muestra lo suficientemente grande.
Ensayo 4, escenario 2: gráfico que demuestra el uso de Grow-A-Little con un tamaño del efecto pequeño, *SD grandes, media de 150 frente a 165, *SD de 50 en cada uno, y tamaños de muestra pequeños de 30
Verde: grupo de control Azul: grupo experimental
No se evidencia ninguna diferencia estadísticamente significativa con un valor p de < 0,05, por lo que no se puede rechazar la hipótesis nula porque el ensayo no tenía un tamaño del efecto lo suficientemente grande o un tamaño de muestra lo suficientemente grande.
Ensayo 5 con tamaños de muestra pequeños y desviaciones estándar pequeñas:
Debido a una pequeña desviación estándar, la diferencia es estadísticamente significativa con un valor p de 0,05. La desviación estándar suele ser un parámetro fijo enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum una población y no puede modificarse, pero el mismo resultado puede obtenerse efectivamente aumentando el tamaño de la muestra. El aumento disminuye el impacto de un valor grande pero fijo de la desviación estándar, permitiendo la detección de diferencias más pequeñas entre losLOSNeisseria grupos analizados.
Ensayo 5, escenario 2: gráfico que demuestra el uso de Grow-A-Little con un tamaño del efecto pequeño, *SD pequeñas de 10 en cada uno, media de 150 frente a 165, y tamaños de muestra pequeños de 30
Verde: grupo de control Azul: grupo experimental
La diferencia es ahora estadísticamente significativa con un valor p de 0,05 debido a las pequeñas *SD.
LosLOSNeisseria investigadores que participaron enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum el diseño de un ensayo clínico aleatorio eligieron un tamaño de muestra que tuviera una potencia del 90% para detectar una diferencia del 20% entre el grupo de control y el experimental, con un nivel de significancia (a 2 bandas) del 5%.
Pregunta 1
Si enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum realidad no hay diferencias enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum las medias, ¿cuál es la probabilidad de que el estudio encuentre una diferencia estadísticamente significativa? ¿Cómo se llama este errorErrorRefers to any act of commission (doing something wrong) or omission (failing to do something right) that exposes patients to potentially hazardous situations.Disclosure of Information?
Respuesta: un errorErrorRefers to any act of commission (doing something wrong) or omission (failing to do something right) that exposes patients to potentially hazardous situations.Disclosure of Information de tipo I (falso positivo). Se trata de una pregunta terminológica y es el típico tipo de pregunta presente enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema NodosumlosLOSNeisseria exámenes, con la potencia insertada como distractor. Consulte el primer gráfico multicolor de arriba: si no hay diferencias entre losLOSNeisseria 2 grupos, entonces solo habría 1 curva de campana, con el corte alfa que describe losLOSNeisseria falsos positivos; por lo tanto, la probabilidad de encontrar una diferencia estadísticamente significativa es del 5%, creando un errorErrorRefers to any act of commission (doing something wrong) or omission (failing to do something right) that exposes patients to potentially hazardous situations.Disclosure of Information de tipo I (falso positivo), porque cualquier sujeto que tenga un valor enENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum el área alfa pertenece a la misma población.
Pregunta 2
¿Aumenta/disminuye/no cambia la potencia si se reduce la beta?
Respuesta: la potencia aumenta si se disminuye beta, ya que la potencia = 1 – beta. Consulte el primer gráfico multicolor.
Pregunta 3
¿Aumenta/disminuye/no cambia la potencia si se aumenta el alfa?
Respuesta: la potencia aumenta si se incrementa alfa, lo que aumenta la probabilidad de falsos positivos; por lo tanto, aumentar alfa no es una forma recomendada para aumentar la potencia. Consulta el primer gráfico multicolor para ver la relación entre alfa y potencia. EnENErythema nodosum is an immune-mediated panniculitis (inflammation of the subcutaneous fat) caused by a type IV (delayed-type) hypersensitivity reaction. It commonly manifests in young women as tender, erythematous nodules on the shins.Erythema Nodosum un examen, se suele utilizar una tabla de contingencia 2 x 2 de la realidad/verdad frente a losLOSNeisseria resultados del estudio/prueba para enmarcar esta pregunta. Es importante entender cómo calcular losLOSNeisseria errores de tipo I y de tipo II.
Pregunta 4
¿Aumenta/disminuye/no cambia la potencia si aumenta la diferencia entre la media del grupo experimental y la del grupo de control?
Respuesta: la potencia aumenta alALAmyloidosis aumentar la diferencia de medias, que es otra forma de aumentar el tamaño del efecto alALAmyloidosis haber menos solapamiento entre las 2 distribuciones. Vea el primer gráfico multicolor.
Pregunta 5
¿Aumenta/disminuye/no cambia beta si aumenta la diferencia entre la media del grupo experimental y la del grupo de control?
Respuesta: beta disminuye si la diferencia media aumenta, ya que hay menos solapamiento entre las 2 poblaciones. Vea el primer gráfico multicolor.
Referencias
Clinical tools and calculators for medical professionals—ClinCalc. Retrieved July 20, 2026, from https://clincalc.com/
Brant, R. (n.d.). Inference for means: Comparing two independent samples [Statistical calculator]. University of British Columbia, Department of Statistics. Retrieved July 20, 2026, from https://www.stat.ubc.ca/~rollin/stats/ssize/n2.html
Otte, W.M., Tijdink, J.K., Weerheim, P.L., Lamberink, H.J., Vinkers, C.H. (2018). Adequate statistical power in clinical trials is associated with the combination of a male first author and a female last author. eLife, 7:e34412. Retrieved July 20, 2026, from https://doi.org/10.7554/eLife.34412
Bland, M. (2015). An Introduction to Medical Statistics. 4th ed., pp. 295–304.
Ellis, P.D. (2010). The Essential Guide to Effect Sizes. Statistical Power, Meta-Analysis, and the Interpretation of Research Results. Pp. 46–86.
Walters, S.J., Campbell, M.J., Machin, D. (2020). Medical Statistics, A Textbook for the Health Sciences. 5th ed, pp. 40–48, 99–133.
Citrome, L., Ketter, T.A. (2013). When does a difference make a difference? Interpretation of number needed to treat, number needed to harm, and likelihood to be helped or harmed. International Journal of Clinical Practice, 67(5):407–41. Retrieved July 20, 2026, from https://doi.org/https://doi.org/10.1111/ijcp.12142
Ioannidis, J.P., Greenland, S., Hlatky, M.A., et al. (2014). Increasing value and reducing waste in research design, conduct, and analysis. Lancet, 383(9912):166–175.
Allen, J.C. (2011). Sample size calculation for two independent groups: A useful rule of thumb. Proceedings of Singapore Healthcare, 20(2):138–140. Retrieved July 20, 2026, from https://doi.org/10.1177/201010581102000213
¡Crea tu cuenta gratis o inicia una sesión para seguir leyendo!
Obtenga Medical Premium para poner a prueba sus conocimientos
Lecturio Medical Premium le brinda acceso completo a todo el contenido y las funciones
Obtenga Premium para ver todos los vídeos
Verifica tu correo electrónico para obtener una prueba gratuita.
Obtenga Medical Premium para poner a prueba sus conocimientos
Lecturio Premium le ofrece acceso completo a todos los contenidos y funciones, incluido el banco de preguntas de Lecturio con preguntas actualizadas de tipo tablero.