Playlist
Show Playlist
Hide Playlist
Secondary Structure – Peptides

-
03 Basic Peptides.pdf
-
Reference List Biochemistry.pdf
-
Download Lecture Overview
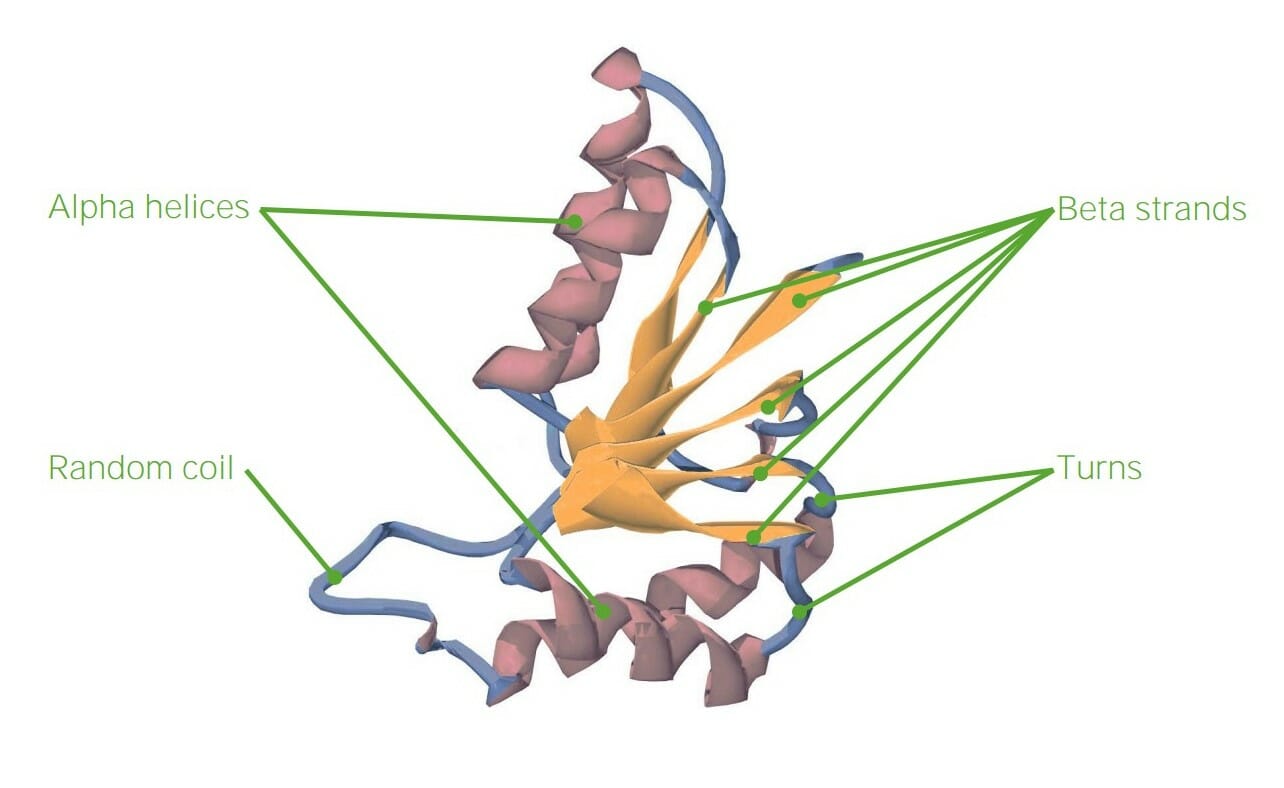
00:01 within a protein; we change the other properties of the protein. 00:01 The secondary structure of amino acid describes regular repeating structures that arise from interactions between amino acids that are close to each other but not distant, that is, amino acids that are typically between about three and ten amino acids apart. 00:17 There are three common structures that I want to discuss here. The first of these structures is shown in blue with coils. These coils are alpha helices and as I noted, Linus Pauling discovered these back in the 1940s and won the Nobel Prize for his discovery. The second type of secondary structure I want to mention are those of the beta strands. Beta strands were also discovered by Linus Pauling, and for also which he won the Nobel Prize, and like the alpha helices they form interactions between amino acids that are close in primary sequence. The actual structure of beta strands is not a coil, like it is in the alpha helix, but instead resembles a pleat, like that found on drapes. 00:59 The third type of structure that's found in proteins, that is predictable, that it involves secondary structure, is what we refer to as reverse turns. Now reverse turns are important, because as you see on the image in front of you, an alpha helix may start, but doesn't stay going on, and on, and on, in fact there is usually some sort of connecting turn that occurs between individual units of beta strands and alpha helices. These reverse turns are predictable based on sequence as we shall see. Now the alpha helix, as I showed earlier, is depicted in this image here. We can see that the alpha helix is a coil, and that coil has a regular repeating nature to it. Further we can see that there's interactions between the carboxyl oxygen and the amine hydrogen as shown on here. These interactions between the carboxyl oxygen and the amine hydrogen give rise to hydrogen bonds, and hydrogen bonds are very, very important for stabilizing the structure of alpha helices. They are also very important, as we will see, in stabilizing the structure of beta strands. Beta strands as I noted have a structure that resembles a pleat. Now individual beta strands can form inside of proteins, but as you can see in this image, beta strands in one part of the protein, can interact with beta strands in another part of the protein, and give rise to a structure that is commonly referred to as a beta sheet. Now on the right I've shown sequences here of individual beta strands and the interactions between those beta strands to form beta sheets. There are two different sets of interactions here, and for our purposes it doesn't really matter which one is there. In both cases we see that the forces that hold together the beta strands in a beta sheet form are also hydrogen bonds like what we saw in the alpha helix, but in this case, the zigzag structure of the backbone of each of the strands is different from the coil that we saw in the alpha helix. 03:06 Reverse turns differ from the alpha helices and beta strands in not having a repeating structure like we saw, either the coil or the pleats, instead, beta turns are fairly short sequences consisting of about four amino acids as shown on the screen here. Now the composition of the amino acids comprising beta turns varies a bit, but one of the interesting things that we see when we compare many reverse turns is that frequently the amino acid proline is involved in those turns. Proline you may recall from the earlier discussion is an amino acid that has less flexibility than the other amino acids do. 03:45 As a result of that lack of flexibility, proline tends to have restrictions on the angles that it can project out and allow amino acids to be attached to. Consequently proline is very commonly found in reverse turns. Another interesting amino acid we commonly see in reverse turns is the amino acid glycine. Now glycine, you remember, had the R group that contained only hydrogen and had what I described as the most flexibility. So in combining the amino acid with the least flexibility with the one that has the most flexibility, changes in structure are possible that would not otherwise be possible. 04:22 One of the things that we can do knowing the structure of all the amino acids, is again use a computer to ask the question, what types of structures do each of these amino acids have and how do these structures allow an amino acid to be a part of an alpha helix, a beta strand or a reverse turn. Now what the computer will do is take that information and give predictions or numerical values assigned to each one, that will indicate the tendency of each amino acid to be in any of these structures. So we can say for example, alanine has a value of 1.41 for being in an alpha helix, a value of 0.72 for being in a beta strand and a value of 0.82 for being in a reverse turn. What does this mean? Well in general, the higher the value that the computer assigns, the more likely that amino acid will be found in the structure shown. These plots and these evaluations for all 20 of the amino acids are known, and you can see the some amino acids have a greater tendency to be in one structure than another. 05:25 Alanine for example, is more likely to be found in an alpha helix than it is to be found in a beta strand or a reverse turn. But you'll notice also that no amino acid has a value of zero, meaning that there is no amino acid that isn’t found in some of the structures, just the frequency is all that really matters. Now we can use this information to help us to predict what types of secondary structure appear in a protein if we know the sequence of the protein. So for example if we have a protein that has a section that has alanine, that has a high value for alpha helix, adjacent to a glutamic acid that has a high value for an alpha helix, adjacent to a leucine, that also has a high value for an alpha helix, that we might begin to think that this portion of a protein has an alpha helical structure. Well, this is shown for some of the different amino acids here, so for example, as I noted for alanine and glutamic acid, you can see they have high values of being in an alpha helix. By contrast, isoleucine and valine have high values and will tend to be found in beta strands. And as I mentioned earlier, glycine and proline have high values for being located in reverse turns. Now the beauty of this analysis is that with fairly good accuracy, the scientist can predict the secondary structure of a protein based on its primary sequence. Now the same is not true for predicting the tertiary structure as I will discuss in just a bit. 06:56 Now there are proteins that are interesting in the sense that they only have primary and secondary structure. These are proteins that are known as fibrous proteins, they have very little tertiary structure which I will describe in just a minute. Proteins that are fibrous in nature have important functions in our body, so for example, our hair is comprised of a protein known as keratin. The glue that sticks ourselves together is a protein known as collagen. If we look at silk for example, we're talking about a protein that's called fibroin. Now the interesting thing about these proteins is as I said, they are fibrous in nature. The protein I showed you earlier, showed an alpha helix and then bends and then it showed beta strands and then bends and so forth. These fibrous proteins will not have those bends. They will typically have a repeating structure of either an alpha helix, or a beta strand, or some other type of helix, which is what we find in collagen that is a repeating over and over and over and over. Now this can be seen an electron micrograph showing some of the proteins and their fibrous nature as you can see on the screen here.
About the Lecture
The lecture Secondary Structure – Peptides by Kevin Ahern, PhD is from the course Biochemistry: Basics.
Included Quiz Questions
Which of the four levels of protein organization has a regular repeating structure arising from interactions of nearby amino acids?
- Secondary
- Primary
- Tertiary
- Quaternary
What are the main forces that were described as stabilizing secondary structure?
- Hydrogen bonds
- Covalent bonds
- Disulfide bonds
- Ionic bonds
- Carbon-carbon bonds
What do the protein structures of collagen, keratin, and fibroin (the protein of silk) have in common?
- They do not have a tertiary structure.
- Their structures cannot be predicted from their primary amino acid sequences.
- Hydrogen bonds between carboxyl groups help stabilize their structures above the primary level.
- Their alpha-helix and beta-strand sequences have the same proportions of amino acids.
- Their structures may show forward and reverse turns.
Which of the following amino acids have a high propensity for reverse turns?
- Glycine
- Alanine
- Glutamic acid
- Valine
- Isoleucine
Which of the following statement is FALSE regarding the secondary structure of proteins?
- There are 4 structures used to describe the secondary structure of proteins.
- Alpha helixes and beta-strands were discovered by Linus Pauling.
- In alpha-helixes, hydrogen bonds are formed between carboxyl oxygen and the amine hydrogen.
- Beta-sheets are groups of beta-strands from different parts of a protein.
- Proline and glycine are frequently found in reverse turns.
Author of lecture Secondary Structure – Peptides

Kevin Ahern, PhD
Customer reviews
5,0 of 5 stars
| 5 Stars |
|
2 |
| 4 Stars |
|
0 |
| 3 Stars |
|
0 |
| 2 Stars |
|
0 |
| 1 Star |
|
0 |
I understand very well, thank you Professor Kevin, these help me a lot
My name is Barbara, I'm from Colombia and I really like your videos Mr. Kevin, because I think the content is easy to understand.
