Playlist
Show Playlist
Hide Playlist
Matched Studies – Observational Studies (Study Designs)

-
Slides 07 ObservationalStudies Epidemiology.pdf
-
Reference List Epidemiology and Biostatistics.pdf
-
Download Lecture Overview
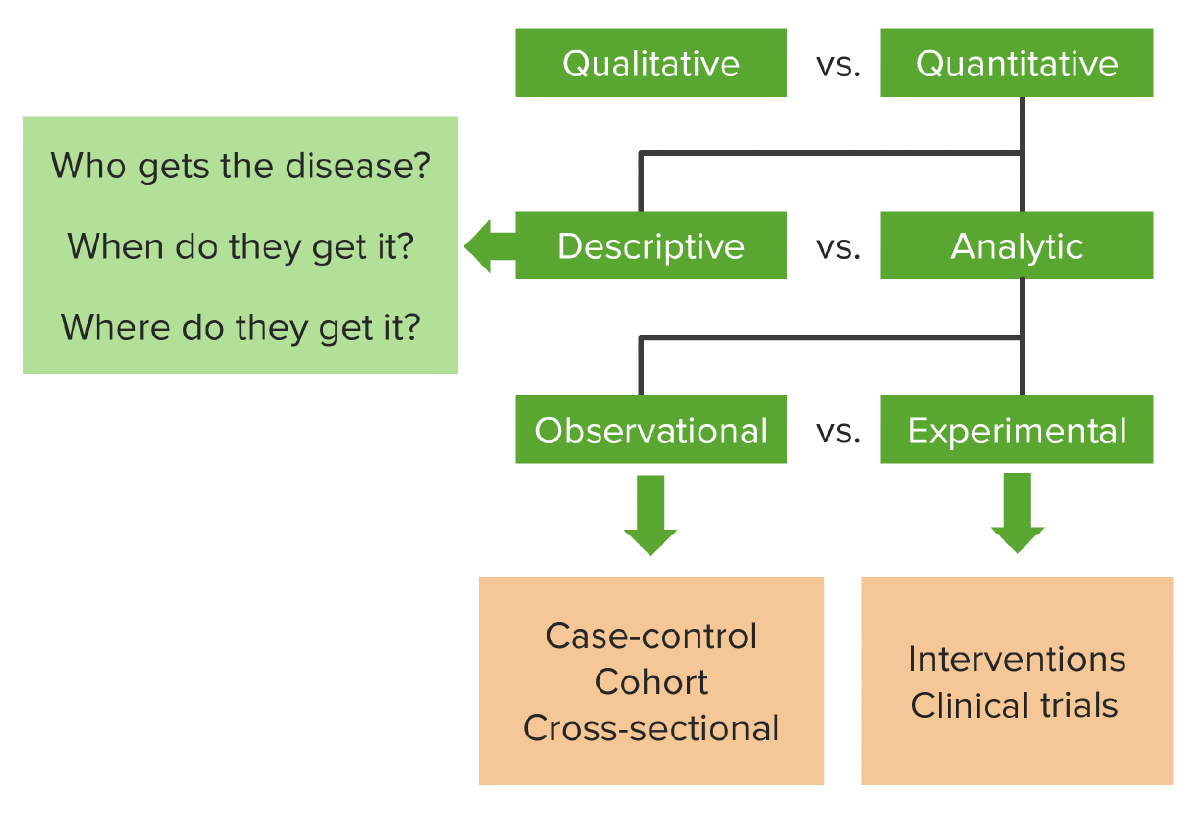
00:01 So when we want to minimize the influence of extraneous factors that may confound our findings, we try to match our cases with our controls in a case-control environment. If you recall from our lecture on biases, confounding was a classic problem we encounter a lot in our studies and we like to stratify by that variable that is the confounder to control for. What does that mean? It means we match or exclude or stratify analyses based upon that variable. So matching is a process of selecting the controls so that they are very similar to the cases in certain characteristics. Common characteristics tend to be of the classic confounders; age, sex, race, socioeconomic status, maybe occupation, maybe smoking status and so forth. So let's say men are more likely than women to develop lung cancer, that's not necessarily the case, this is just an example that's entirely hypothetical. Let's also say that men are more likely than women to have smoked. And we're going to run a case-control study here. Sex is going to be a confounder because gender is associated both of those outcomes. By the way, I'm using the word sex and gender interchangeably; they're technically different constructs, so bear with me as I fumble through those particular words. 01:21 One way to control for this is to match cases and controls by sex. What does that mean? It means that each case, each person with lung cancer, is compared only to a specific control in the other group of the same sex. So men are compared to men and women are compared to other women, and the twain shall never be crossed. So the percentage of men across cases will be equal to the percentage of men across controls is another way of approaching it. 01:48 I'll say it again. I can either match individually or through percentages. One is called individual matching and the other is called group or frequency matching. In individual matching, I'm comparing one individual to another individual. In group or frequency matching, I just make sure that the numbers or proportions of the individuals of interest are equal in my two groups. Individual matching, group or frequency matching. 02:17 So let's review what we've learned so far. The cross-sectional study is when we ascertain the exposure and the outcome status simultaneously. It's great for surveys. It's great for measuring associations between things that don't change, typically, like gender, handedness, your height, your eye color and so forth. The case-control study is great in other contexts and the case-control study is characterized by the fact that you ascertain the outcome first, the lung cancer and then you wait or look backwards to see what the exposure status was, the smoking. 02:53 It's great when the outcome is rare, as in rare diseases, or in outbreak investigations. 03:00 And the cohort study is when we ascertain the exposure status first, we wait for time to pass to see if the outcome manifests. It's the default observational design. It's easy to understand, we all love it, but it can be expensive.
About the Lecture
The lecture Matched Studies – Observational Studies (Study Designs) by Raywat Deonandan, PhD is from the course Types of Studies.
Included Quiz Questions
What is the purpose of matching cases with controls in case-control studies?
- Minimize extraneous factors that may bias or confound the findings
- Preventing bias due to demand characteristics or the placebo effect
- Preventing the selection bias and the accidental bias
- Minimize the false positive and false negative rates
- To make incidence rates as accurate as possible.
Which of the following best describes matching?
- A process of selecting the controls so that they are similar to the cases in the characteristic of interest.
- A process of selecting the controls so that they are dissimilar to the cases in the characteristic of interest.
- A process of randomizing the control and study group at the beginning of a study.
- A process of gathering many randomized control trials and aggregating their data.
- A process of selecting cases only in one gender when the study is looking at outcomes in both genders.
Author of lecture Matched Studies – Observational Studies (Study Designs)

Raywat Deonandan, PhD
Customer reviews
5,0 of 5 stars
| 5 Stars |
|
5 |
| 4 Stars |
|
0 |
| 3 Stars |
|
0 |
| 2 Stars |
|
0 |
| 1 Star |
|
0 |
