Playlist
Show Playlist
Hide Playlist
Immunoglobulin Genes and Recombination – Lymphocyte Development

-
Slides Adaptive Immune System.pdf
-
Reference List Immune System.pdf
-
Download Lecture Overview
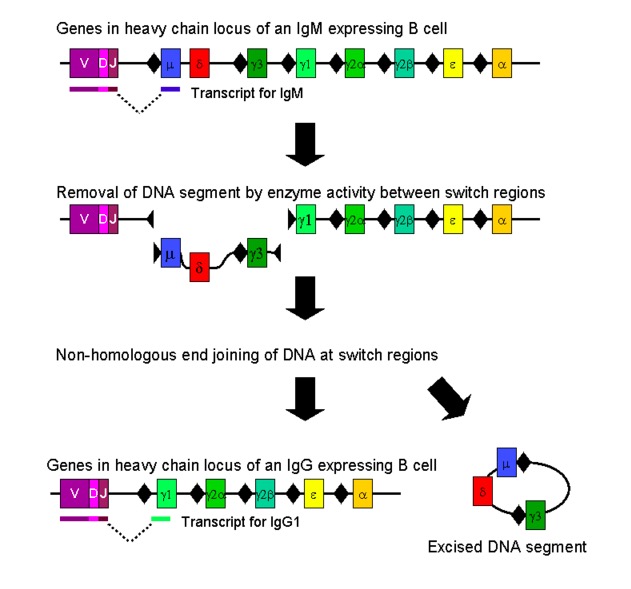
00:01 We heard a few seconds ago, how from a relatively small number of genes, you can make millions and millions and millions of different antibody molecules; and millions and millions and millions of T-cell receptor molecules. 00:13 So let’s have a look at how that works. 00:15 This is the immunoglobulin heavy chain gene locus, happens to be on chromosome 14; doesn’t really matter where it is, but happens to be on chromosome 14. 00:24 And it consists of a number of gene segments, I sometimes call mini genes. 00:31 And essentially there are four bunches of gene segments for the immunoglobulin heavy chains. 00:37 So bunch of segments shown in blue here that are called the V or Variable region gene segments. 00:44 And we have about 40 of these. 00:47 So one’s called VH1, VH2, VH3, VH4, and so forth; round about 40 in total. 00:53 We then have a bunch of D segments, Diversity segments shown in green here, and we have about 27 or so of those. 01:04 Downstream or free prime in the DNA sequence from the D segments, there’s a bunch of J segments; we have about half a dozen of those indicated in red here. 01:14 And then further downstream we have a total of nine Constant region gene segments, just one is shown here - Cµ. 01:21 But there are a total of nine. 01:24 So on the heavy chain gene locus, four bunches of gene segments: V - Variable, D - Diversity, J - Joining, and C - Constant. 01:39 The light chains are organized in a somewhat similar way. 01:41 They’re organization isn’t exactly identical but essentially there are bunches of gene segments. 01:48 And the main difference really is that in the light chains there are no Diversity gene segments. 01:54 So it consists simply of a bunch of V segments, J segments and C segments, without any Diversity segments. 02:02 So upstream, just like in the heavy chain, upstream of each Variable sequence is a Leader sequence that takes the protein to the cell surface when it’s been translated. 02:14 And for the light chains, we have two different versions: kappa (k) and lambda (λ). 02:21 This is λ shown here. 02:23 Again, happens to be on chromosome 22, that’s not really that important unless you’re obsessed with each chromosomes particular genes are on. 02:30 The important point is, there are a bunch of V gene segments, not just one but several, and around about 30 Vλ gene segments. 02:39 And then the way that the Joining segments and the Constant segments is organized is a little bit different between heavy chain. But as you can see, there are a number of J segments and a number of Constant segments. And if we were to look at the k light chain, the other variant of the light chain. Again it’s on a different chromosome, so the heavy chain’s on one chromosome, k light chain on another chromosome, λ light chain on another chromosome. But the arrangement is similar; bunch of gene segments. Remember in the light chain, no D segments. So heavy chain - VDJ, light chain just V and J, and then together with the Constant segments. So for the k light chain we have about 40 Variable, 5 or 6 or so Joining. It varies from one individual to another but that’s sort of typical. And normally would be five Joining segments for k, and then Constant region as you can see. So let’s now look at how the immunoglobulin genes recombine in B-cells. 03:38 What you can see in front of you are the immunoglobulin heavy chain genes in what is called the germ-line configuration. And these will be present in this configuration, in nerve cells, in liver cells, in all the different cells in the body. 03:51 And it’s only in the B-lymphocyte that these genes will recombine in order to generate an antigen receptor. 03:59 And in each individual B-cell, the B-cell will choose a different combination of V, D and J gene segments in order to create a different B-cell receptor. 04:11 So you may have one B-cell that recognizes Streptococcus for example, a different B-cell might recognize Staphylococcus. Another B-cell, Candida and so forth. 04:20 And it needs a different antigen receptor to recognize each different antigen in a specific way. 04:26 So to take this B-cell for an example, this B-cell has decided to use the D segment, D2, and has placed it next to the J segment, J4. 04:40 That’s the first stage. 04:42 The second stage is to select one out of the 40 Variable segments and place it next to the already recombined D and J segment. 04:52 So this B-cell decides to use V4 and places it next to the already recombined D2 and J4. 05:04 So in this B-cell you’ll have a continuous stretch of DNA, that is V4D2J4. 05:13 That DNA is then transcribed into the primary RNA transcript and that is processed into messenger RNA. 05:23 And that primary transcript includes the first two Constant region genes, Cµ that will encode an IgM antibody and Cδ that will encode an IgD antibody. 05:37 And by alternative splicing of the primary RNA transcript, you produce messenger RNA that either will encode a IgM antibody using Cµ as in this particular example here, or alternatively using Cδ to encode an IgD antibody. 05:57 And the important point is, the same V, D and J sequence is being used for both of those classes of antibody. 06:03 So both the IgM antibody and the IgD antibody in a single B-cell will be of identical specificity. 06:11 So if the IgM is against Staphylococcus, the IgD will be against Staphylococcus. 06:16 That messenger RNA is then translated into protein and the Constant region gene as the name suggests encodes, the Constant region of the antibody molecule, in this case an IgM antibody. 06:29 And the Variable region is made up of three different gene segments - the V segment, the D segment and the J segment. 06:40 So although the Variable region in the protein is just referred to as the Variable region, it’s actually encoded by three different gene segments; not only the Variable gene segment, but also the Diversity and the Joining gene segments. 06:54 Within the Variable region of antibodies, there are three regions that are hypervariable. 07:00 They vary even more between one antibody and another. 07:03 And these three hypervariable regions are referred to as the CDRs. 07:08 That stands for Complementarity Determining Regions. 07:11 So we have CDR1, CDR2 and CDR3. 07:16 And as you can see from this illustration, CDR1 and CDR2 are encoded entirely by the Variable gene segment, whereas CDR3 is encoded by a combination of V, D and J gene segments. 07:33 What that means is that CDR3 is much more variable, because it’s the combination of one out of 40 Variable, one out of 27 Diversity, one out of six J; whereas at least initially, the CDR1 and CDR2 are not nearly as diverse because they can only be selected from one out of 40 Variable gene segments. 07:56 So the antibody is then produced, this is the heavy chain you see here. 08:01 The light chains undergo a similar recombination process, but remember there are no D segments in the light chains. 08:08 So it’s just a recombination of one out of a number of V segments being placed next to one out of a number of J segments. 08:18 So on this particular diagram we can see how the CDR1, CDR2 and CDR3 hypervariable regions sit towards the tip of the antibody and are present in both the heavy chain and the light chain. 08:33 So the Variable region of the light chain and the Variable region of the heavy chain are next to each other, and then below that is the Constant region of the heavy chain and the light chain.
About the Lecture
The lecture Immunoglobulin Genes and Recombination – Lymphocyte Development by Peter Delves, PhD is from the course Adaptive Immune System. It contains the following chapters:
- The Immunoglobulin Genes
- Genetic Recombination of the Heavy Chain
Included Quiz Questions
What is the approximate number of variable gene segments in the human heavy chain immunoglobulin loci?
- 40
- 27
- 9
- 6
- 2
What are the 2 different forms of light chain immunoglobulins?
- Kappa and Lambda
- Alpha and Beta
- Lambda and Mu
- Kappa and Beta
- Kappa and Mu
What is the main difference between the gene segments of immunoglobulin light chains (l) and heavy chains?
- The light chain gene segments do not have a diversity segment.
- The light chain gene segments show much great diversity.
- The light chain gene segments are longer and more complicated.
- The light chain gene segments have a significantly shorter variable region.
- The light chain gene segments are not essential for construction of a complete immunoglobulin.
What is the primary purpose of light and heavy chain gene segment recombination?
- Creating antigen receptors that can recognize each individual antigen in a specific way
- Creating antigens that are antibiotic resistant
- Creating antigen receptors that do not attack the host
- Creating immunoglobulins without light chains.
- Creating a variable region that differs between light chains and heavy chains.
The hypervariable regions within a variable region of an immunoglobulin is referred to as which of the following?
- Complementarity-determining regions
- Diversity regions
- Leading regions
- Constant regions
- Joining regions
Author of lecture Immunoglobulin Genes and Recombination – Lymphocyte Development

Peter Delves, PhD
Customer reviews
5,0 of 5 stars
| 5 Stars |
|
2 |
| 4 Stars |
|
0 |
| 3 Stars |
|
0 |
| 2 Stars |
|
0 |
| 1 Star |
|
0 |
This is a fantastic teacher with great didactic. I would probably take 10 times longer to understand the subject if I were to read about it without prior knowledge.
The professor explains with clarity and organization which makes it easier to understand.
