Playlist
Show Playlist
Hide Playlist
Blinding – Interventional Studies (Study Designs)

-
Slides 08 InterventionalStudies Epidemiology.pdf
-
Reference List Epidemiology and Biostatistics.pdf
-
Download Lecture Overview
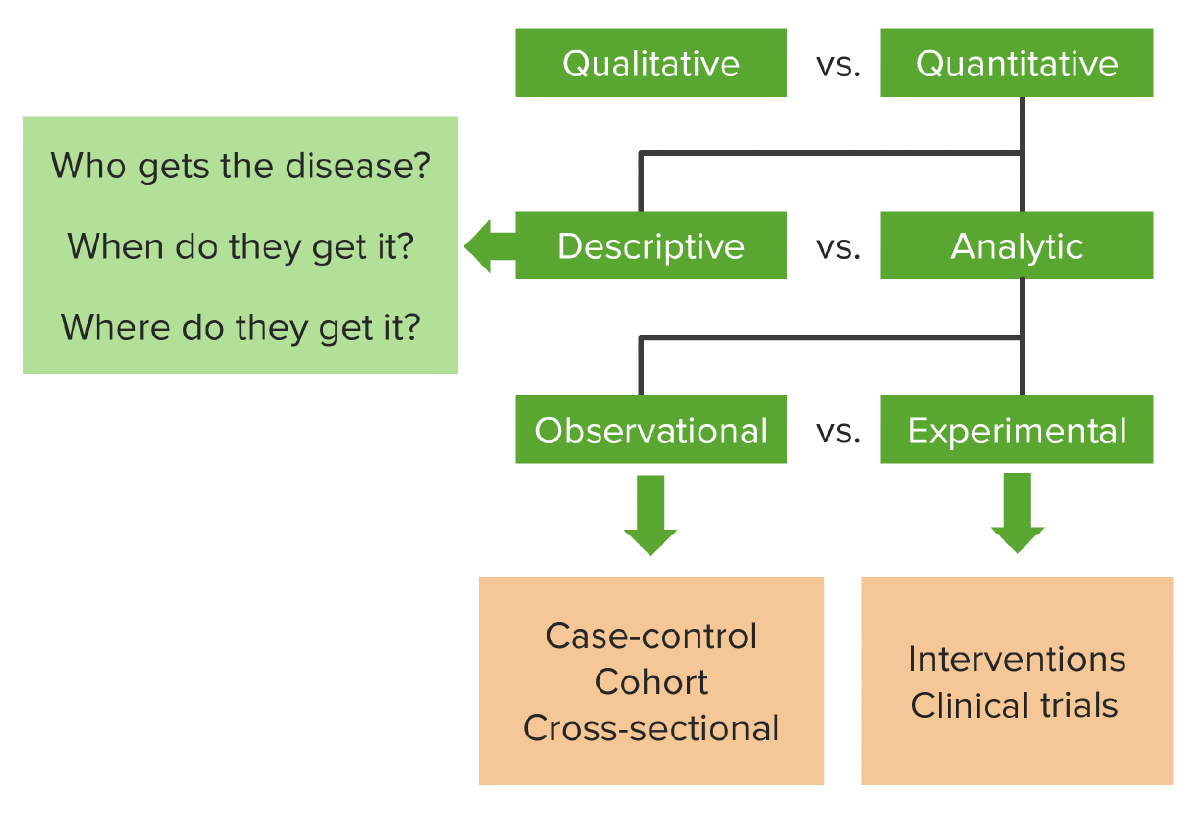
00:01 How do I account for these two biases, Hawthorne effect and Rosenthal effect? We account for them with blinding. Blinding is when some parties in the experiment don't know who got the drug versus who got the control group therapy. There are different kinds of blinding. 00:23 Single-blindedness is when the subjects themselves don't know whether or not they're getting the drug or the other therapy, how could they not know? Well sometimes the therapy is disguised in such a way to make it indistinguishable from the control group therapy. Let's say it's a placebo pill, so you're getting a pill, that's the new drug and the control group is getting a placebo, which looks exactly the same but contains nothing that's medically effective, you can't tell which one it is. Obviously if you stop to think about it, there are some cases in which you cannot single blind. Can you imagine a case when you're running an RCT and there's no possible way to blind the subject to whether or not they're getting the therapy? I can imagine it right now. It's possible to do an RCT on the effects of massage, maybe on pain management, so one group is going to get a massage and the other group is going to get what, there's nothing I can imagine that resembles a massage sufficiently that you don't know you're not getting a massage, so some things you cannot blind for. So again single-blindedness is when the subjects themselves don't know what therapy they're getting. Double blindness is when neither the subjects, nor the investigators know which subjects are getting what. How did this happen? Well they seal it off in envelopes. We decided beforehand, in the randomization process, which group will be the test group and which group will be the control group and that's sealed off. And the investigator does not know until the seal is broken at the end of the study. Is there such a thing as triple blinding, what you think? Can you think of a third party in this relationship that may be requires blinding of their own? Well there is, the data analyst. We have subjects, we have investigators and we have the people who work with the data. So modern RCTs sometimes require this third type of blinding to maintain that everything is as objective as possible. 02:19 Now let's talk about placebo for a second. I mentioned that sometimes the control group will get this thing called a placebo. The word literally means "I please", because a placebo is meant to please a person. You take this, a drug that does not work and maybe it pleases you. So a placebo by definition is a simulated or medically ineffective treatment designed to deceive a patient into thinking they're getting an actual treatment. Traditionally it was what was given to all RCT control groups, but we no longer do that typically, we use the next standard treatment, as I mentioned. Now you've probably heard of something called the placebo effect. Sometimes we call this the physiological effect produced by placebo. 03:05 Now that particular definition is useful because it speaks to the idea that there is a physiological effect involved. Your body is responding to a placebo thinking that it is actually a therapy. 03:17 There's some conflict amongst the specialists over whether or not it is a physiological response. Some people argue it is entirely a perceptive response that maybe the placebo effect only works on things like perceived pain. You can do your own research on this topic, it is a fascinating field to look into. Now imagine we have a study that looks like an RCT, but it lacks the random allocation, what do you think we call that? Well we call that quasi-experiment. A quasi-experiment is an experiment that lacks the randomized nature of the allocation and very often it lacks blinding as well. But quasi-experiments are enormously useful and really quite popular in international health studies and in program evaluation studies. So here's how it works, we have a study population, much like the randomized controlled trial example. We don't randomize, but we decide who gets in the treatment group versus who gets in the control group. Again, this is not a cohort study, remember a cohort study did not involve randomization either, but cohort study the subjects chose where to go, they chose whether or not they are going to be exposed to the thing in question or not. In a quasi-experiment, much like every experiment, the investigator chooses which group they're in, not randomly in this case. Here is an example. Let's say we're looking at Rwandan communities and Rwandan communities are beset with a problem with waterborne diseases and sometimes the tap water is turbid resulting in a need to boil the water. People often don't know how to intensify turbid water or how long to boil it. So let's say we introduce an educational radio broadcast in Rwanda to test whether or not teaching people how to identify and boil this water can reduce in fewer cases of waterborne disease. By the way this is a classic case for a quasi-experimental design, any sort of media intervention is ready-made for a quasi-experimental design. This is how it works. We have our Rwandan communities, we choose two of them, not randomly, I choose one that's going to receive my radio broadcast, I choose another that's not going to receive the radio broadcast. I wait some time and I see whether or not there is lower or higher cases or incidence of waterborne diseases. Keep in mind there are some things I cannot control in this scenario. I cannot prevent people from traveling from one community to the other. I cannot prevent people from communicating to each other, say "Hey did you hear about that radio broadcast?" And I cannot control for other factors that may be influencing the rate of waterborne disease, like an NGO showing up and also giving a private lecture on how to identify turbid water. Having said all that, the quasi-experimental design is an excellent design for program evaluation or evaluating large-scale community interventions like this. 06:18 Let's take a moment now to talk about internal versus external validity, they're both measurements of what we call validity, which is an important concept in scientific proof, but they're distinctly different. Internal validity is the extent to which the associations or relationships within your study are real. Did you measure something that's real. So in other words, it is the extent to which the causal relationships are meaningful. Is the approximate truth of the relationship observed meaningful? The way that we establish internal validity is to say, did I control for confounding? Did I control for any of the other biases that we've talked about in another lecture on bias? External validity on the other hand is when I'm able to generalize from my findings to the rest of the world, to my reference population. 07:06 An externally valid study has results that are applicable to everybody else. Okay
About the Lecture
The lecture Blinding – Interventional Studies (Study Designs) by Raywat Deonandan, PhD is from the course Types of Studies.
Included Quiz Questions
Why should the current standard of care treatment be administered instead of a placebo?
- It is unethical to withhold potential life-saving/preserving treatment that is known to be effective.
- It is more cost-effective to use a treatment that already exists than trying to fabricate a placebo that resembles the treatment.
- Subjects are more likely to guess they are receiving a placebo; by giving a treatment they are less likely to guess their group assignment.
- In many cases, it is ethical to knowingly give members of the control group a therapy that has no positive effect.
- It is never correct to the control group standard of care treatment.
What is the placebo effect?
- The tendency of any medication or treatment, even an inert or ineffective one, to exhibit results simply because the recipient believes that it will work.
- A tool used so subjects in a study aren’t able to tell whether they are receiving the treatment or not.
- The effect caused by triple blinding an RTC that allows for extrapolation of data by data scientists.
- The effect that is perceived by subjects who are in the treatment group of a study.
- The measurement of a physiological effect in the control group of a study.
What term is used when the researcher, subject, and data analysis do not know which group a subject is assigned?
- Triple blinding
- Double blinding
- Single blinding
- Hawthorne effect
- Rosenthal effect
Which of the following describes the quality of a study that allows it to be generalized to the real world?
- External validity
- Internal validity
- Minimal variance
- Accuracy
- Specificity
What makes a quasi-experiment different from an RCT?
- It typically lacks randomization and blinding.
- It is an observational study
- It is a qualitative research study.
- it looks at data retrospectively.
- The researcher is causing the exposure.
Author of lecture Blinding – Interventional Studies (Study Designs)

Raywat Deonandan, PhD
Customer reviews
5,0 of 5 stars
| 5 Stars |
|
5 |
| 4 Stars |
|
0 |
| 3 Stars |
|
0 |
| 2 Stars |
|
0 |
| 1 Star |
|
0 |
