Playlist
Show Playlist
Hide Playlist
Experiments and Observational Studies

-
Slides Statistics pt1 Experiments and Observational Studies.pdf
-
Download Lecture Overview
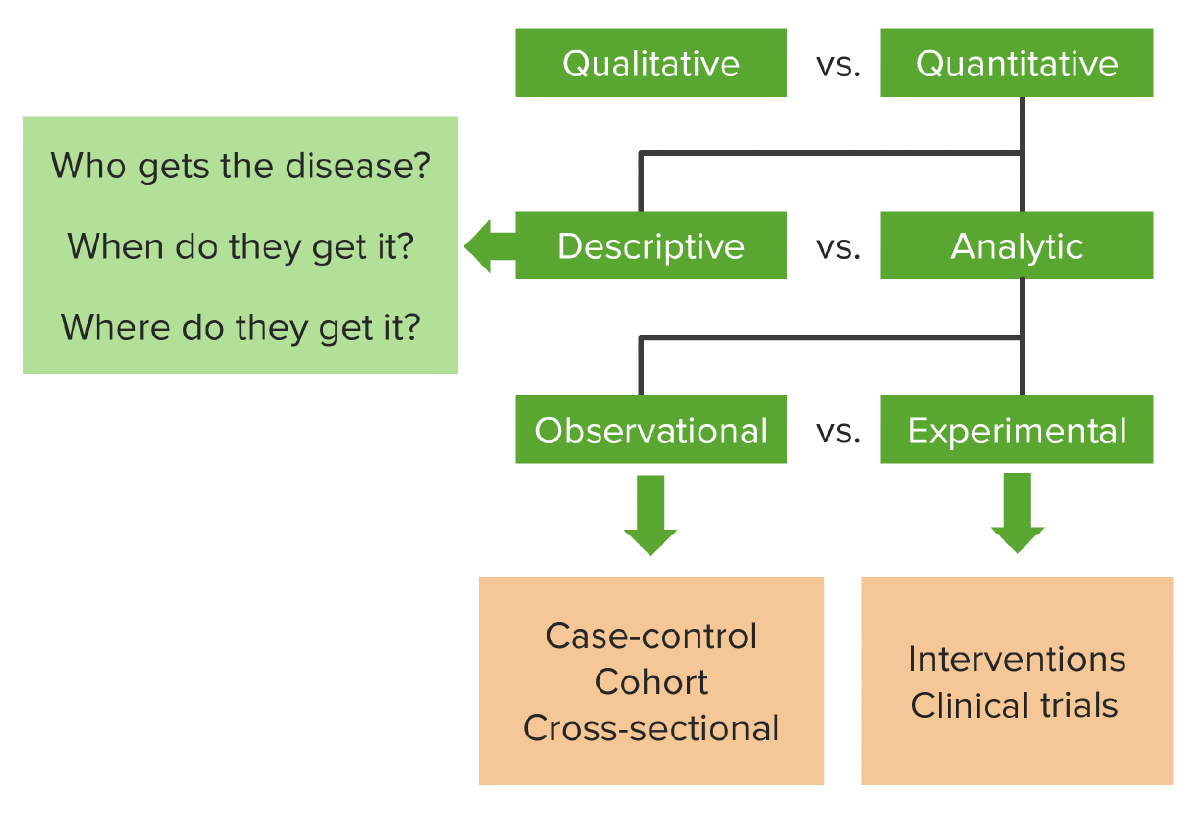
00:01 Welcome back for Lecture 10. Where we're gonna discuss experiments and observational studies. 00:05 Let's start with an example, just to see why we do experiments and how we can establish cause and effect between two things. 00:15 Let's look at how music affects the academic success of primary and secondary school students, in terms of grade point average. 00:23 There's a study done in the high school in California that show that the music students had an overall grade point average of 3.59 while non-music students had an overall grade point average of 2.91. 00:35 16% of music students had all A's, while only 5% of the non-music students had all A's. 00:41 So let's look at the questions that we can ask here. 00:44 One, does this provide evidence that music students enjoy better academic performance than non-music students? Two, are there other possible explanations for the difference in grades between the two groups? And three, is there any way to prove such a thing? Well, let's look at how we can do it as an observational study first. 01:03 The goal in the example is to find an association between the music and the grades. 01:08 How was the study conducted? Well, it's not a survey because we didn’t go around asking everybody whether they took music classes and what their grade point average was. 01:17 We're just observing the students in their natural state and looking at their choice of music education and their grade point average. 01:26 The choices are not assigned by the investigator, but the investigator simple observing what the students are doing. 01:33 This type of study is called an observational study. 01:36 Treatments aren't assigned to anybody, we're just observing everything in its natural state. 01:41 Because the study is based on past grades and past information about the students, we call it a retrospective study. 01:48 Formerly, a retrospective study is any observational study in which the previous information conditions behaviors or outcomes are observed. 01:58 The question is, can we infer a cause and effect relationship from the observational study? Well, let's look at the possible issues with the study that, that was done. 02:09 First of all, we only look at one high school which is not likely to be representative of the entire United States. 02:15 We claim that music education causes the increase in GPA and that claim makes the assumption that there are no other differences between the two groups. 02:25 But perhaps music students have better work habits or better study habits, better parental support or any other number of things, that would also influence their grade point average. 02:36 In other words, several lurking variables might be in play here and we can't necessarily say that the taking of music classes increases overall grade point average. 02:47 In general, we can't infer cause from an observational study. 02:51 So why bother doing them? Well, there's a plenty of useful things that can come out of an observational study, we use them a lot in health studies. 03:01 They're often retrospective because we often identify people with the particular disease and then look into their history and ancestry to get information about things related to that particular disease. 03:14 Retrospective studies however, they often have errors, we often based them on historical data and people often, it's quite simply people forget stuff. 03:24 So somewhat better approach might be to observe individuals over time, record variables of interests and then see how things turn out. 03:33 How might we approach the study for the high school students in a better way? Or in the high school example maybe we could start by observing the students who have not yet taken the music lessons, track their academic performance over several years and then compare those who later choose music versus those who don't. 03:51 Let's look at some further notes on this study. 03:53 This would be a perspective study. 03:56 This is a study in which we identify subjects in advance and then collect data as events unfold. 04:02 We can learn a lot from observational studies but there's no guarantee that we have found the most important variables. 04:09 For example, students who choose to study an instrument may still differ from those who don’t in ways we didn’t observe. 04:17 So this, these things that we don’t observe maybe what's causing the differences rather than the choice of studying music itself in terms of academic performance. 04:26 So what's the big picture? What’s the take away here? Well, whether an observational study is retrospective or prospective, it's not possible to ascertain a cause relationship between the two variables of interests. 04:38 Let's look at another example. 04:41 In 2007, a larger than normal number of cats and dogs, developed kidney failure and died. 04:49 Investigators were using an observational study to figure out why. 04:52 How would you design such a study? And would it be retrospective or prospective? Well, let's answer that question. 04:59 This would have to be a retrospective study, since sampling all pets is impractical, it makes the most sense to find the ones who were sick, ask about their diet and whether they were exposed to toxins and ask about maybe other possible causes of their kidney failure. 05:17 In order to determine cause and effect, we can't use an observational study. So what can we do? Well, in the music and grades example, we might be able to take a group of third graders, assign half of them to take music lesson, and the other half not to, and then compare the grade point averages in the groups at the end of high school. 05:34 This is an experiment, an experiment is the study in which the investigator manipulates one or more variable in order to examine the changes in the variable of interests. 05:44 Here, the variable of interests is GPA and the variable being manipulated by the investigator is whether or not the student takes music classes. 05:52 How do we design an experiment and what makes a good experiment? Well, the first thing is, we require our subjects to be randomly assigned to a group, this ensures that the groups are relatively homogenous so that only the things that are different between then are the values of the explanatory variable. 06:12 In other words, the only things that are different between the two groups are the variables that are being manipulated. 06:18 This can help us determine whether changes in the responses are caused by the changes in the explanatory variable. 06:24 Experiments study the relationship between two or more variables, at least one explanatory variable or what we call a factor is the thing that's manipulated by the experimenter. 06:36 We have at least one response variable, this is the thing that we're examining too, the changes in. 06:42 This is what's measured by the experimenter. 06:44 And at the end, we compare the responses for the different groups in the experiment for the subjects that have been treated differently. 06:51 All right, so let's just look at some vocabulary pertaining to experiments. 06:56 Subjects or participants are individuals on whom experiments are performed. 07:01 Subjects is the word that reserve for human experimental units. 07:06 Experimental units are non-human individuals on whom experiments are performed. 07:12 So subjects is reserve for humans experimental units is basically everything else. 07:17 The specific values that in experimenter chooses for a factor are known as the levels of that factor. 07:23 In our example, the levels of the explanatory variable which was whether or not the student takes music lessons is, there were two levels, one they take music lessons, the other level was that they don't. 07:36 The combination of specific levels from all the factors that an experimental unit receives is known as a treatment. 07:42 And the example we only had one factor with two levels so there were only two treatments. 07:47 So let's go back to the example where we look at pet deaths, the deaths of cats and dogs were ultimately traced to a contamination of some brands of pet food but the manufacturer claims the good is safe, it has to be tested first. 08:02 So if we were designing an experiment to test the new food, what would be the treatments and what would be the response variable? Well, the treatments are ordinary size portions of the two dog foods, the new one and the one that is claim to be safe. 08:18 So we're gonna do it under the old one and we're gonna feed some animals, the new one that's, is claim to be safe. 08:25 The response variable is the result of a veterinarian's assessment of the pets overall health. 08:31 Let's look at some principles of experimental design. 08:35 So we can see how we design a useful experiment. 08:38 One of the key components of a good experiment is control. 08:41 We need to control sources of variations other than the factors that we're testing by making conditions as similar as possible for all the treatment groups. 08:50 This helps us look at the variation between the groups and make conclusions about the cause of the differences. 08:56 We control both the factors and the sources of variation and we control factors by assigning subjects to different factor levels to see how the responses will change at those different levels. 09:08 We control other sources of variation to prevent them from changing and affecting the response variable. 09:15 When we set up an experiment, we need to randomly assign our experimental units to treatment groups. 09:21 This randomization doesn’t eliminate the effects of outside sources but it spreads the effects of the outside sources equally across the treatments. 09:30 Randomization allows for control of outside influences that the experimenter might not even be aware of. 09:37 The rule of thumb is, control what you can, randomize the rest. 09:43 We need to be able to replicate our experiments, there's two types of replication. 09:49 The first is to apply each treatment to more than one subject and the second type of replication is to be able to repeat the experiment for different population of experimental units. 10:00 Replication enables us to estimate the variability of the results that we get. 10:06 We can’t draw conclusions about what's going on in the world unless we repeat our results. 10:12 We might have gotten that's something that's anomalies in one experiments, so we have to be able to do it again and reproduce similar results in order to make inferences about the population. 10:21 Replication of entire experiments with the controlled sources of variation is an essential principle in science for the reasons that I just stated. 10:30 Blocking is sometimes useful in experiments, and let's look at what blocking is. 10:36 Blocking is a scheme in which we divide our sample into groups based on a characteristic that is not directly under study and we perform this same experiment in each group. 10:46 Blocking is extremely useful when there are important differences among our participants. 10:52 Maybe their sex, their profession or some other important difference. 10:57 These are all factors that we're not controlling for. 11:00 The idea is that we group similar individuals in blocks and randomize the treatments within each block. 11:07 This is not required but it's often helpful. 11:11 Let's how we -- see how we diagram an experiment. 11:15 Remember from before that one of the -- that the three roles of data analysis are, make a picture, make a picture and make a picture. 11:23 Let's see how we make a picture of an experiment. 11:26 We make a diagram and here's for a simple experiment, here's what we're doing. 11:32 We start with random assignment of individual to treatment groups, and so once we have that random assignment we have group one and then group two and then group one, we give treatment one. That's the next part of the diagram. 11:45 Treatment two goes to group 2, and once we've assigned those we compare the results between the two groups. 11:52 Let's look at an example of how we diagram an experiment. 11:56 We have this manufacturer of a new fertilizer and it claims that we're gonna grow juicier and tastier tomatoes with it. 12:01 You wanna set up an experiment to investigate this claim and you wanna see if you can get by with half of the recommended dose. 12:09 You have 24 plants available. How might we design an experiment to answer these questions? Well, there’s one factor and one response variable. What are they? The response variable, maybe we give a measure on a scale of one to ten of juiciness and taste. 12:27 A factor would be the dosage of the fertilizer and it has levels none, that would be a control, half the recommended dose and the full recommended dose. 12:38 There are three treatments, one factor at three levels and we randomly assign the 24 plants to the 3 groups so we have 8 plants per group. 12:48 We give each plant a particular group -- in a particular group the same treatment and then we compare the results at the end. 12:56 Here's the diagram of the experiment. 12:59 We have the 3 groups, so we start with random assignment and we randomly assign 8 plants to each of the 3 groups. 13:06 In group 1, we give treatment 1 which is the control or no fertilizer. 13:12 In the second group, we give half the recommended dose, that's our treatment 2, and then, group 3 we give treatment 3 which is the full dose of the fertilizer. 13:22 At the end we compare the juiciness and tastiness scores among the 3 groups. 13:27 Let's make some notes on this experiment. 13:31 This is an example of what we call a completely randomized experiment, and let's formalize what this is. 13:36 It's the simplest type of design for an experiment, and the key property of it is that each experimental unit has an equal chance of receiving any of the treatments that are available. 13:46 We develop a completely randomized experiment by randomly assigning the same number of experimental units to each group and we assign people or individuals or experimental units to groups at random. 13:59 Now, when we talk about comparing the differences among the groups, we wanna know what makes a big enough difference to -- to conclude it, the treatments causing the change and the response. 14:11 This is where we come to the question of statistical significance. 14:15 Small differences between the treatment groups are usually attributed to chance but the real question is, are the difference that we see, are they about as big as what we might expect to see from randomization or by chance or are they bigger than that? If the differences are bigger than what we would expect to see by chance, then we attribute these to the differences in the treatments and if this happens we say that the differences are statistically significant. 14:41 We'll formalize this in later chapters. 14:45 All right, so let's look at the differences between experiments and surveys. 14:48 Both experiments and surveys require randomization, but they're done in different ways. 14:53 The randomization itself is done in different ways. What are the differences? Well, one difference is that sample surveys try to estimate population parameters, so the sample needs to be as representative of the population as possible, and we talked about this in the section on surveys. 15:09 Experimental units and experiments are not always drawn randomly from the population as individuals are in surveys. 15:17 A medical study for instance, might only wanna look at patients who have a particular disease. 15:22 This group that we're looking at for this experiment on the medical study isn’t represented of the whole population but only in the group that -- of people that have this disease. 15:32 The randomization is any assignment of treatments to the experimental units and not in how we draw our individuals. 15:40 In experiments again we wanna use control treatments. Basically, we wanna establish a baseline. 15:46 What is a control treatment? Well, control treatment is in essence of baseline measurement used to help decide whether a treatment has an effect on the response. 15:57 Typically the control is to apply no treatment at all. 16:01 In the tomatoes example, the control is the treatment where no fertilizer is used. 16:05 The group of experimental units to which the control treatment is assigned is called the control group, naturally. 16:12 Blinding is a great principle and a great practice to use in experimentation. 16:18 Some times and most times in experiments, it's best not to know. 16:22 What do we mean by that? Well, let's look at an example. 16:25 Suppose we wanna advice the company on which brand of soda to stock in the vending machines. 16:30 You set up an experiment to see which of these 3 competing brands your co-workers prefer. 16:35 You do blinding in the taste test. Your co-workers may have a brand to which they are already loyal. 16:42 One might like Pepsi, one might like Coke. 16:45 They're likely to stick to that brand if they know what brand they are drinking. 16:49 It's best to disguise the cola brand as much as possible. 16:54 This is called blinding, where the person receiving the treatment doesn’t know what treatment they're receiving. 17:01 In general, experimental units should be blinded during the experiment. 17:07 In other words, the experimental units should not know what treatment they're receiving as receiving this knowledge can influence how they react to the treatment and thus can have an influence on the response. 17:19 It’s sometimes it's even better if no one knows. 17:23 The experimenter may also be able to influence the responses by knowing what treatment each subject is receiving. 17:29 Let's look at different types of blinding. 17:32 It’s often best to make sure that neither the experimenter nor the subject knows what treatment the subject is receiving. 17:39 If only one of the parties, the subject or the experimenter knows what treatment the subject is receiving, then the experiment is said to be single-blind. 17:49 If neither the experimenter nor the subject knows what treatment the subject is receiving then the experiment is known as double-blind. 17:57 You hear a lot about double-blind studies, that's exactly what this means. 18:01 In the tomato experiment, we don’t want the people judging the taste to know what tomatoes got the fertilizer. 18:07 This would make the experiment a single-blind experiment because certainly we would know what treatment we're giving the tomatoes. 18:14 We might not want the people carrying for the plants to know which ones were being fertilized. 18:21 In case that they might treat them in different ways, so if we assign a group of people to take care of the plants for us instead of doing it ourselves and they don’t know what they're doing to the plants either, then this experiment would be double-blind. 18:36 Placebos. These are often used in health studies and this is basically faking out the subjects. 18:43 This is one way of blinding and also way of control. 18:46 What are the uses of placebos? Well, what is a placebo in the first place? It's a fake treatment, they just looks just like the real treatments. 18:55 This is one of the best ways to blind subjects from knowing whether or not they are receiving the treatment. 19:00 Again, very common in medical studies, sugar pills are often use as placebos. 19:07 Sometimes people treated with a placebo may still improve because they feel like they should because they took something. 19:13 This is known as what's called the placebo effect. 19:17 Placebo controls are highly effective at blinding and as a control treatment at the same time. 19:23 And so the best experiments in some should be randomized, comparative, double-blind and placebo-controlled. 19:29 Those are the four key things that you want in an experiment. 19:33 Now, let's take a closer look at blocking and how we do it. 19:37 We looked at a -- we kinda look at what blocking is but we haven’t done anything with it yet. 19:42 Let's go back to the tomato experiment, maybe we wanted 18 plants but the nursery would want to only have 12, and so we had to go to another nursery to get 6 more. 19:52 Maybe these nurseries care for their plants a little bit differently. 19:54 Maybe we wanna block by nursery. 19:57 Maybe wanted to design our experiment so that the stores do not mask the effect of the fertilizer. 20:03 We can put the plants into blocks by the store that they came from. 20:07 Again, blocking is the practice of putting groups of similar experimental units into separate groups. 20:13 Here's a diagram of how we would block the tomato experiment. 20:19 The tomato plants came from two different nurseries. 20:21 We conduct two parallel fertilizer experiments. 20:24 One for the tomatoes from each store and we combine the results. 20:28 Here's the diagram. We have the 12 tomato plants from store A and the 6 from store B. 20:34 We set up two blocks, the 12 from store A and the 6 from store B. 20:40 And block A, we assign 4 plants to each treatment, and then, so we have 4 plants getting no fertilizer, 4 plants getting half a dose and 4 plants getting the full dose. 20:52 We compare the juiciness and tastiness in that block at the end. 20:56 We do the similar thing for the plants from store B. 21:00 When we talk about confounding, what we mean is, we have variables that kind of mask each other's effects. 21:05 In other words, we can’t really separate the affect of one variable from the other. 21:10 Let's look at confounding in a more formal way. 21:12 Sometimes the levels of one factor are associated with the levels of another factor, and we say that these 2 factors are confounded. 21:20 What this does is it makes it difficult to examine each factor individually. 21:25 For instance, soil moisture has an effect on how tomato plants grow. 21:31 The fertilizer changes the soil moisture concentration depending on the dose. 21:35 If we investigated the effect of both soil moisture and the fertilizer dosage on the tomato plants, the 2 would be confounded since the fertilizer dosage changes the moisture concentration in the soil There's several things that can go wrong when we design experiments and we wanna be careful to avoid these things. 21:54 Let's look at some issues to be aware of in designing experiments. 21:58 We don’t wanna give up on a study just because we can't do an experiment. 22:03 In many cases an observational study can be helpful -- at least in identifying relationships between factors and responses. 22:10 We wanna be aware of confounding, this can cause a lot of problems in the interpretation of the effect of different factors. 22:18 Finally, we don’t wanna blow the budget on the first run of an experiment because your experiment might not work. 22:24 You wanna try to be able to replicate it so some good advice is to try to -- try a small pilot study in the beginning, and then run the full experiment later. 22:34 What we've done in this lecture is we talked about experimentation and the differences between experiments and observational studies. 22:41 We talked about how to design experiments that are useful and give useful information about the relationship between the response and the explanatory variable. 22:51 We also talked about how cause and effect were established. 22:54 We looked at different types of experimental designs and we looked at common issues that come up in experimental design. 23:00 This is the end of Lecture 10 on experimental design, we'll see you back here for Lecture 11.
About the Lecture
The lecture Experiments and Observational Studies by David Spade, PhD is from the course Statistics Part 1. It contains the following chapters:
- Experiments and observational studies
- Why do Observational Studies?
- Designing an Experiment
- Principles of Experimental Design
- Diagramming an Experiment
- Experiments and Surveys
- Placebos and their Uses
- Randomized Block Designs
Included Quiz Questions
When we use records from past observations to evaluate the responses, what type of study have we conducted?
- We have conducted a retrospective study.
- We have conducted a survey.
- We have conducted a prospective study.
- The information provided in this question is not sufficient to determine what kind of study has been conducted.
- We have conducted a cohort study.
Why are observational studies useful?
- Observational studies allow us to examine the relationship between two variables.
- Observational studies allow us to establish cause and effect relationships between two variables.
- Observational studies allow us to determine whether we have found the explanatory variables that have the largest effect on the response.
- Observational studies allow us to evaluate the placebo effect.
- Observational studies are useful to determine the maximum safe dose of a drug.
What is a difference between an observational study and an experiment?
- In an experiment, the researcher assigns treatments, while in an observational study, treatments are not assigned.
- In an observational study, the researcher assigns treatments, while in an experiment, treatments are not assigned.
- Experiments can be used to study relationships between two variables, while observational studies cannot be used in this way.
- An observational study allows us to infer cause and effect relationships, while experiments do not.
- Only observational studies regularly look at toxicity outcomes.
What is the relationship for a variable that masks the effect of another variable?
- We say that these variables are confounded.
- We say that these are lurking variables.
- We say that these variables are factors.
- We say that these variables are treatments.
- We say these variables are atypical.
What are ‘experimental units’?
- Non-human individuals on whom experiments are performed
- Numbers involved in experiments
- The one who conducts the experiments
- The one who pays for the experiments
- The one who create hurdles in the experiment
Who are the ‘subjects’ in the context of experiments?
- Individuals on whom experiments are performed
- Numbers involved in experiments
- The one who conducts the experiments
- The one who pays for the experiments
- The one who creates hurdles in the experiment
What is a control treatment?
- A control treatment is a baseline measurement used to help decide whether a treatment has an effect on the response.
- A control treatment is a complex tool used to help decide whether a treatment has an effect on the independent variable.
- A control treatment is a false replication of the original treatment.
- A control treatment is a method of removing outliers.
- A control treatment is one that has no effect on the response.
What is the type of blinding for a study in which only one of the parties (i.e. either the subject or the researcher) knows what treatment the subject is receiving?
- Single-blind
- One-blind
- Triple -blind
- No-blind
- Single-bind
What type of blinding is described when neither of the parties (i.e. either the subject or the researcher) knows which treatment the subject is receiving?
- Double-blind
- Both-blind
- One-blind
- Triple-blind
- Double-bind
Author of lecture Experiments and Observational Studies

David Spade, PhD
Customer reviews
5,0 of 5 stars
| 5 Stars |
|
5 |
| 4 Stars |
|
0 |
| 3 Stars |
|
0 |
| 2 Stars |
|
0 |
| 1 Star |
|
0 |
