Playlist
Show Playlist
Hide Playlist
Genetic Code


-
16 Advanced RNA&GeneticCode.pdf
-
Reference List Biochemistry.pdf
-
Download Lecture Overview
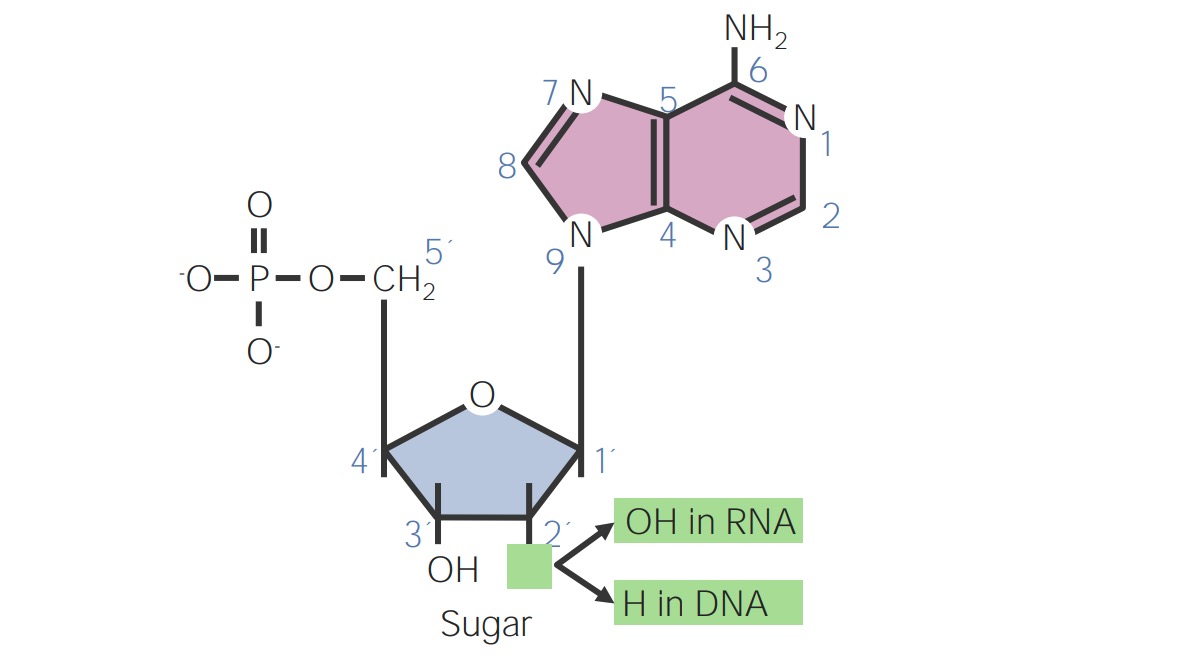
00:01 Well, the last place that I will talk about here where the RNAs get involved is, of course, in the carrying of the genetic information to the ribosome via the genetic code. 00:10 The genetic, as I have discussed in another presentation, is a three base sequence that determines ultimately how protein were made. 00:19 Each three base sequence called a codon in a messenger RNA specifies the incorporation of an amino acid into a growing polypeptide chain. 00:29 Now you can see the actual genetic code that's up on the screen here. 00:32 And it's beautiful in its simplicity and also beautiful in what functions it performs. 00:39 As I have noted before, there is a sequence called a start codon that is involved in starting the synthesis of every protein that's made in the cell. 00:49 That start codon is known as AUG and it codes from methionine as you can see in the first column near the bottom. 00:56 There are also three codons called stop codons that tell the ribosome this is the place to stop incorporating amino acid into a growing peptide chain. 01:06 They are known as UAA, UAG and UGA, as you can see on the screen. 01:12 Now the genetic code really is what we all rely on to exist. 01:17 Without the genetic code and the proper use of the genetic code, life as we know would not be possible. 01:24 The genetic code is universal. That's one thing that is very interesting about it and it says a lot about our relationships to every cell on the face of the earth, because, every cell on the face of the earth is using the same genetic code. 01:40 That turns out to be not only just an interesting fact but also important when we think about how we want to use the genetic code to make products in biotechnology. 01:52 So for example if I were interested in producing let's say human growth hormone and I wanna to take a bacterial cell and have that bacterial cell make that human growth hormone. 02:04 I could actually do it surprisingly easily. 02:08 I could take the coding sequence for the human growth hormone and remove all the introns and all the things that would be happened to in the eukaryotic cells. So that I have all the spliced version of that gene and put that gene into a bacterial cell under the control of the promoter. 02:26 If I take that gene and do that the bacterial cell will transcribe through that coding region for the human growth hormone. 02:34 And then ribosome will grab it and start to translate it. 02:37 And since the genetic code is the same for a bacterium as it is for my cell the bacterium will actually start producing the human growth hormone protein. 02:47 That's a remarkable thing that we can do as a result of this common genetic code across organisms. 02:54 Now another consideration with the genetic code and it's one that isn't commonly discussed is the genetic code relies completely on accuracy. 03:03 We saw during the marginals on DNA replication, the extreme links that cells went to in terms of proofreading and correcting errors and correcting damage in the DNA; because, we knew that the integrity of the DNA was critical. 03:19 And the reason it comes down to be critical is because the proteins that are made from it have to be accurately made and if they are not accurately made there can be a severe consequences. 03:28 But it's not just DNA replication that was important. 03:31 The process of splicing was also important. Remember that RNA polymerase copied the DNA and in eukaryotic cells those little intervening pieces had to be removed. 03:43 And the removal of those pieces has to be precise; because, if their one nucleotide one direction the other wrong way then the entire message is ruined and the protein that would be made from it is ruined. 03:56 The last thing that has to happen relative to the actual sequences is the processing of these individual RNAs. 04:03 The processing to make them so that they are translatable, to modify the RNAs as necessary to improve their function or to facilitate their function is essential. 04:15 So without these things going on the genetic code would have no meaning. 04:20 Now it's interesting that the translation process is not as accurate as DNA replication. 04:26 For a cell, let's say a bacterial cell, a bacterial cell makes an error in replication about 1 time in every 10 million bases. 04:37 That's a pretty remarkable set of accuracy, especially when you consider it's working at a thousand nucleotides a second. 04:44 That's a lot of faster than any typers and I don't know any typer who can type that accurately. That's remarkable. 04:50 But translation doesn't need to be as accurate as DNA replication. Now that's the sort of flip side this thing. 04:58 We need the accuracy to have the translation proceed properly. 05:02 But the translation can actually have a few errors. 05:07 If the translation has errors the proteins that would be made will not function. 05:13 They will be destroyed and as long as those errors are relatively infrequent, most of the protein that's made will be functional. 05:22 Now if we have an error in the DNA that has very different consequences; because, an error in the DNA well that ruins everything all the way down to the line. 05:30 And as DNA is being passed from one generation to the next, once you have got an error then that error carries forward. 05:37 So errors in DNA replication have major implications to the genetic code and the translation of proteins. 05:43 But errors during the process of translation can be tolerated to some extent. 05:49 So the ultimate function of the genetic code or the ultimate value of the genetic code is then the accuracy of all these processes and the last part of it is putting the right amino acid onto a transfer RNA. 06:05 Now the transfer RNA, of course, is the molecule that carries the amino acid to the ribosome. 06:09 And in the ribosome the anti-code unloop of the transfer RNA pairs with the codon. 06:15 That can be fairly accurately established. 06:17 However, if the transfer RNA has brought the wrong amino acid in even through the codon-anticodon pairing is good, the wrong amino acids will be incorporated into the protein. 06:29 So it's very important thing that the amino acid at the 3 prime end of the transfer RNA be the one that corresponds to the anticodon at the anticodon loop. 06:40 This sequence that's there is actually read by an enzyme called the aminoacyl-tRNA synthetase and it does what you see in the screen here. 06:50 It reads the anticodon and puts the right amino acid onto the 3 prime end. 06:56 Aminoacyl-tRNA synthetases have to get it right. 07:00 If they don't get it right then everything else is out the door. 07:04 So the ultimate integrity of the genetic code is residing in the catalytic activity of these enzymes. 07:11 So how do they perform what they do? They actually look at both ends of a transfer RNA. 07:18 That means they have to be able to span from the bottom where the anticodon is up to the top where amino acid gets put on. 07:27 So I tell you a secret here. Most aminoacyl-tRNA synthetases don't span the entire distance from the anticodon up to the place where the amino acid is attached. They are not physically big enough. 07:39 And this was realized when people begin to analyze the 3D structure of a transfer RNA. 07:46 And when they did that they discovered that the transfer RNAs that we typically write in a 2D form, as you see here as a flat structure, really isn't a flat structure, but in fact is bent about in the middle. 07:57 And that brings the end that gets the amino acid onto it much closer to the anticodon. 08:04 So that the span of aminoacyl-tRNA synthetase can actually cover both of those areas at once and have the proper amino acid put onto the transfer RNA. 08:14 So when the proper amino acid is linked, as we have seen here, then the transfer RNA is ready to go to the ribosome and be translated. 08:23 Now this is pretty important to get right. 08:25 So cells invest a fair amount of accuracy and a fair amount of energy into the synthetases that do this. 08:34 There is one synthetase made for each amino acid. That is its specific. There are 20 synthetases that are used to put amino acids onto tRNAs. 08:45 One for each of the amino acids that goes into a protein. 08:50 Now those synthetases have to be able to read slightly different anitcodons at the end; because, the code is redundant meaning that some amino acids are specified by more than one set of codons. 09:04 But those synthetases have built that into them and, as a result, are able to put the proper amino acid onto the tRNAs. 09:12 Now there are two different types of synthetase that cells have. 09:16 One is called a type 1 synthetase and these synthetases put the amino acid not actually on the 3 prime end it's on the end that has the 3 prime end But they scrolled over 1 and put on to the 2 prime hydroxyl They kind of cheat. The type 2 synthetases actually do what I always said along is that the put on the 3 prime end. That is they put on the end and on the 3 prime hydroxyl. 09:40 In ether case it's going on to the same piece of DNA and it's going on to the orientation you see. 09:46 It just depends which portion of the ribo sugar that it's actually going onto. 09:51 Now interesting thing about the aminoacyl-tRNA synthetases is like the DNA polymerases that we saw, aminoacyl-tRNA syntheses also do proofreading. 10:03 So, as I said, translation doesn't have to be a 100% accurate but it's important enough that the aminoacyl-tRNA synthetases are checking after they have put the amino acid onto the tRNA. 10:15 They are checking to see that they got the right amino acid corresponding to the antiocodon. 10:19 This helps improve the accuracy of the process I have just described to you. 10:25 Well, I have talked in this lecture a lot about RNA. I have talked about how RNAs are processed. I have talked about how RNAs can perform functions including their own regulation and catalysis upon other RNAs. 10:38 In the end very end we have seen how the RNAs have to be carefully processed in order to be translated. 10:45 And I hope what I have left with you in this discussion is the importance not only the function of RNA but the things that RNA is doing in making proteins.
About the Lecture
The lecture Genetic Code by Kevin Ahern, PhD is from the course RNA and the Genetic Code.
Included Quiz Questions
Which of the following is true regarding aminoacyl tRNA synthetase?
- It reads the anticodon in the tRNA to put the right amino acid on the tRNA.
- It is responsible for transcribing tRNAs.
- It attaches random amino acids to the end of a tRNA.
- It is found in 64 different forms — one for each codon.
- It reads the codon in the tRNA.
Which of the following is not correct regarding the genetic codon?
- The viral genetic codon is composed of a set of twenty-seven codons which direct the synthesis of viral proteins in the host cells.
- The genetic codon is composed of a set of three bases or nucleotides which code for one amino acid.
- The genetic codon is universal, comma-less, co-linear, unambiguous, and non-overlapping.
- The gene-polypeptide parity says that a specific gene gets transcribed to a specific mRNA which directs the synthesis of a specific polypeptide chain.
- The genetic codon establishes the relationship between the sequence of bases in nucleic acids and the sequence of amino acids in proteins.
Which of the following is not matched correctly regarding the genetic codon?
- Redundant genetic codon — signal for the end of translation process during protein synthesis
- Sense codons — code for the amino acids
- AUG codon — codes for methionine as well as serves as an initiation site during the translation process
- Signal codons — these code for the start and stop of the translation process
- Stop codons — in mRNA, amber (UAG), ochre (UAA) and UGA (opal) codons act as the translation termination signal
How does the aminoacyl-tRNA synthetase enzyme help to improve the accuracy of the translation process?
- The aminoacyl-tRNA synthetase ensures the attachment of the correct amino acid to the corresponding tRNA molecule.
- The aminoacyl-tRNA synthetase ensures the attachment of release factors at the stop codon during the translation process.
- The aminoacyl-tRNA synthetase ensures the release of amino acid from the corresponding tRNA and helps in its attachment to the growing polypeptide chain.
- The aminoacyl-tRNA synthetase ensures the continuous movement of ribosomes on the mRNA during the translation process.
- The aminoacyl-tRNA synthetase helps in the formation of the ribosome by facilitating the joining of smaller and larger subunits of the ribosome.
Where do type-1 and type-2 aminoacyl-tRNA synthetase enzymes attach amino acids?
- Amino acids are attached to the 2’OH and 3’OH of terminal A of the tRNA, respectively.
- Amino acids are attached to the 1’OH and 3’OH of terminal A of the tRNA, respectively.
- Amino acids are attached to the 3’OH and 2’OH of terminal A of the tRNA, respectively.
- Amino acids are attached to the 2’OH and 1’OH of terminal A of the tRNA, respectively.
- Amino acids are attached to the 1’OH and 2’OH of terminal A of the tRNA, respectively.
Author of lecture Genetic Code

Kevin Ahern, PhD
Customer reviews
5,0 of 5 stars
| 5 Stars |
|
5 |
| 4 Stars |
|
0 |
| 3 Stars |
|
0 |
| 2 Stars |
|
0 |
| 1 Star |
|
0 |
